0x0 hive命令
启动
hive --service metastore #启动元数据库
hive --service hiveserver2 #启动hiveserver2
hiveservices.sh start #通过脚本启动
bin/beeline -u jdbc:hive2://hadoop102:10000 -n atguiguhive客户端
bin/hive #启动hive客户端
#可以配置打印表头 见附录4
bin/hive -help
bin/hive -e "select id from student;" # -e 不进入客户端执行sql
bin/hive -f # -f 执行文件内sql
touch hivef.sql
select *from student;
bin/hive -f /opt/module/hive/data/hivef.sql #执行文件
bin/hive -f /opt/module/hive/datas/hivef.sql > /opt/module/datas/hive_result.txt #结果写入文件
hive> dfs -ls /; #查看dfs文件
bin/hive -hiveconf mapred.reduce.tasks=10; #启动带配置hive配置
常见的配置设置—不赋值的话可以直接看当前值
set mapreduce.job.queuename;---得到default
alter table person set tblproperties("EXTERNAL"="TRUE")--修改内外部表
set mapreduce.job.reduces=3;--设置分区数用于cluster by---不用时设成-1
set hive.exec.mode.local.auto=true;--本地模式
set mapreduce.job.queuename=hive;--虽然名字是mapreduce,但是实际是你启动客户端时显示的计算引擎,非常好用。
set hive.exec.dynamic.partition.mode=nonstrict;--动态分区
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;--项目里。0x1 hive数据类型
常用基本类型
INT
BIGINT=常用
DOUBLE
STRING=常用,可变长度,2G
BOOlEAN=可用0,1代替
TIMESTAMP=可用字符串或BIGINT代替
decimal(10,2)=表示总最多10位(整数超过8报错),固定2位小数(不足会补齐,多了截断)。插入字符串'11.333'、'13'都行
date=半标准 '2020-10-10'常用集合类型
ARRAY=array<string>,类似于对象,类型在建表时固定
MAP=map<string, int>,通过map名字[key值]访问对应的value
STRUCT=struct<street:string, city:string>,通过数组名字[索引]访问隐式类型转换
任何整数类型都可以隐式地转换为一个范围更广的类型
整数、float、数值型string能隐式转换为double
int —bigint
int—-float
boolean不能转化为任何其他类型
强转
- cast(实参 as 数据类型) 比如cast(‘1’ as 1)
0x2 hive架构
hive:基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表(创建表的时候分隔符自然会处理hdfs表路径下的文件),并提供类SQL查询功能。
本质
其实相当于hadoop的一个客户端(不是分布式,客户端不存在分布式)
表的元数据metastore存在mysql(自带derby不好)(表名,表所属库,默认default,表拥有者,列/分区字段,表类型(是否外部),所在目录等)
本质:将HQL转化成MapReduce程序
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
HQL作用步骤
hive自带和jdbc连接的客户端
hive的DRIVER结合mysql里的metastore
转换为mapreduce程序执行hdfs里的数据
执行得到结果返回客户端
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上hive和数据库的区别:最核心的是处理数据量问题:数据量大所以要存在分布式文件系统中数据仓库的内容是读多写少的。
因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的。
架构
client : 自带cli和beeline通过jdbc连接hive操作:输入操作和返回结果显示,对应不同的命令
driver : hive核心
1. 解析 : 抽象语法树AST/校验字段表存在/SQL语义错误
2. 编译 : 翻译成mapreduce逻辑执行计划
3. 优化 : 谓词下推- 执行 : 把逻辑执行计划转换成可以运行的物理计划
0x3 hive部署
mysql解压-安装
安装mysql/先卸载
连接mysql mysql -uroot -p'123456'
mysql安装
rpm -qa|grep mariadb #检查是否存在mysql
sudo rpm -e --nodeps mariadb-libs #卸载原来mysql
tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar #解压tar包
sudo rpm -ivh #依次执行rpm安装
yum install -y libaio #依赖缺失解决
vim /etc/my.cnf #查看mysql数据所在目录
cd /var/lib/mysql` `sudo rm -rf ./* #删除原来数据
sudo mysqld --initialize --user=mysql #初始化数据库
cat /var/log/mysqld.log #查看密码
sudo systemctl start mysqld #启动服务
mysql -uroot -p #登录 Enter password 临时生成密码
mysql> set password = password("root") #修改密码
mysql> update mysql.user set host='%' where user='root'; #修改用户表权限
mysql> flush privileges;hive安装
tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/ #解压
mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive #改名
sudo vim /etc/profile.d/my_env.sh #环境变量
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak #修正日志jar冲突
cp /opt/software/mysql-connector-java-5.1.48.jar $HIVE_HOME/lib #将MySQL的JDBC驱动拷贝到Hive的lib目录下
vim $HIVE_HOME/conf/hive-site.xml #在hive配置mysql数据库 见附录配置1
mysql -uroot -proot #登录mysql
mysql> create database metastore;#创建元数据库
mysql> quit;#退出
schematool -initSchema -dbType mysql -verbose #初始化原数据库
hive --service metastore #启动元数据
hive --service hiveserver2 #启动hiveserver2
#编写执行脚本 见附录3
chmod +x $HIVE_HOME/bin/hiveservices.sh #给脚本添加执行权限hive附录
附录1
hivesite配置mysql数据库
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- Hive元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>附录2
hive-site.xml 用户自定义配置 会覆盖hive-default.xml中的配置
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定存储元数据要连接的地址//指定使用metastore进行连接 -->
<!-- <property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>-->
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- hiveserver2的高可用参数,开启此参数可以提高hiveserver2的启动速度 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
<property>
<!-- 指定存储元数据要连接的地址//指定使用metastore进行连接 -->
<!-- <property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>-->
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- hiveserver2的高可用参数,开启此参数可以提高hiveserver2的启动速度 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和Spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
</configuration>附录3
hive启动脚本
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac附录4
hive-site
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>附录5
hive数据类型测试与实战
--原始数据
--姓名,朋友1_朋友2,儿子1:18_儿子2:19,街道1_城市_编号
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing_1001
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing_1002建表语句
--建立text表,用于输入非格式化的数据
create table person_text(---建表
name string ,
friends array<string>,
child map<string,int>,
address struct<street:string,city:string,mph:int>
)
partitioned by (day string, hour string) --设置分区字段--对应导入时的分区条件的选择
clustered by (name) into 3 buckets --分桶表:用的少
row format delimited fields terminated by ',' -- 列分隔符-不同字段的分隔符必须一致,一般是'/t'制表符
collection items terminated by '_' --MAP STRUCT和ARRAY的分隔符(数据分割符号)--集合中不同元素分隔符必须统一处理
map keys terminated by ':' -- MAP与STRUCT中的key与value的分隔符
lines terminated by '\n' -- 行分隔符,\n可默认不写
stored as textfile;
load data inpath '/input/person.txt' into table person_text partition(day='20200401',hour='12');
drop table person;
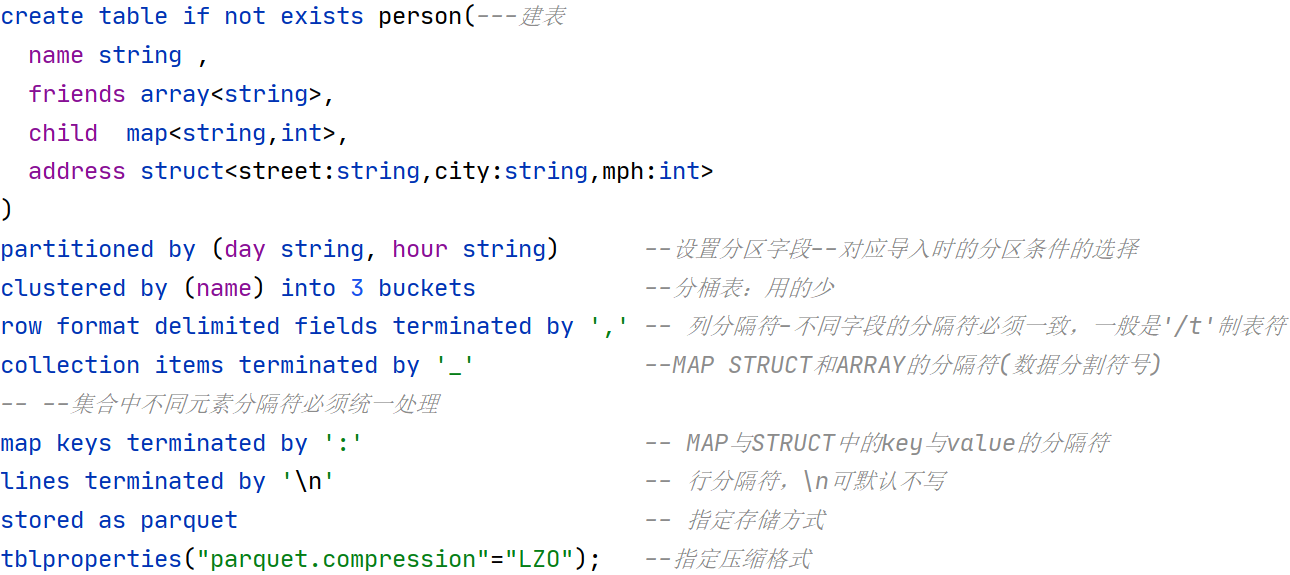
create table person(---建表
name string ,
friends array<string>,
child map<string,int>,
address struct<street:string,city:string,mph:int>
)
partitioned by (day string, hour string) --设置分区字段--对应导入时的分区条件的选择
clustered by (name) into 3 buckets --分桶表:用的少
row format delimited fields terminated by ',' -- 列分隔符-不同字段的分隔符必须一致,一般是'/t'制表符
collection items terminated by '_' --MAP STRUCT和ARRAY的分隔符(数据分割符号)--集合中不同元素分隔符必须统一处理
map keys terminated by ':' -- MAP与STRUCT中的key与value的分隔符
lines terminated by '\n' -- 行分隔符,\n可默认不写
stored as parquet -- 指定存储方式
tblproperties("parquet.compression"="LZO"); --指定压缩格式
show tables;
desc person;
desc formatted person;
--todo 插入数据
insert into person select * from person_text;
select * from person;
select friends[0] from person; --调用array
select child from person;
select child["xiao yang"] from person; --调用map
select address.street from person; --调用struct分区查询
select friends[1],child['xiao song'],address.city ---分区查询
from person
where day = '2020-09-21' and hour = '12';插入操作(注意map<String,String>)切换
--array(值1,值2,值3...) ----三种手动插入数据方式
--named_struct(col1_name,值1,col2_name,值2....)
--str_to_map(字符串参数, 外分隔符1, 内分隔符2),由此推出如果用存贮map字段最好用 map<string,string>存储
alter table person change column child child map<string,string>;----之后上面两种方法才能插入。
insert into table person select 'xiaohua',array('basketball','read'),str_to_map('xiaoming_1,xiaohong_2',',','_'),named_struct('street','ss','city','bb','mph',90),'2020-09-22','14';
insert into table person values('xiaohua',array('basketball','read'),str_to_map('xiaoming_1,xiaohong_2',',','_'),named_struct('street','ss','city','bb','mph',90),'2020-09-22','14');
insert into table person values('jueqian',`array`('benben','yuhong','fengye'),str_to_map('xiaoyang_19,pig_19',',','_'),named_struct('street','shunyi','city','sh','mph',1003),'2020-09-12','23');附录6
hive-site
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>


