0x0 Flink的容错机制
1.一致性检查点(checkpoint)
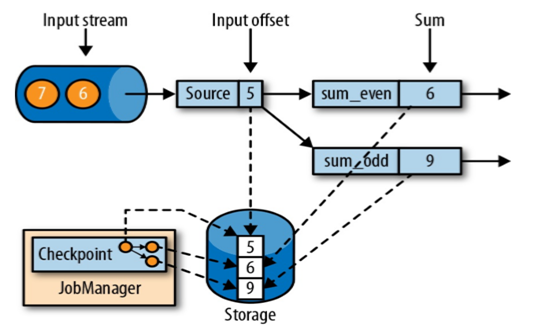
图为一个计算流,计算根据流中的数据将其中的奇数与偶数进行分流统计
Flink故障恢复机制的核心,就是应用状态的一致性检查点
有状态流应用的一致性检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照)
这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候
jobManager发起的检查点命令
//简而言之:如图所示,当输入Source为5时,此时下阶段的sum_odd已经计算完毕(1+3+5=9),sum_even也已经计算完毕(2+4=6),然后此时任务统一全部完成,然后CheckPoint只会存储当前时间节点的数据(5,6,9),因为当前时间节点恰好关于5的所有数据计算完毕.2.从检查点恢复状态
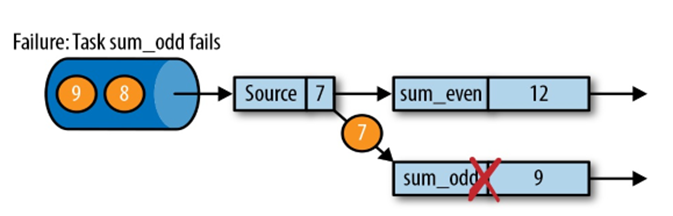
在执行流应用程序期间,Flink 会定期保存状态的一致检查点
如果发生故障, Flink 将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程
2.1从检查点恢复具体流程
- 遇到故障之后,第一步就是重启应用
- 第二步是从 checkpoint 中读取状态,将状态重置,从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同
- 第三步:开始消费并处理检查点到发生故障之间的所有数据,这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置
3.Flink检查点算法
- 基于Chandy-Lamport算法的分布式快照 barrier 对齐
- 核心:将检查点的保存和数据处理分离开,不暂停整个应用
//API
public class FlinkCheckPoint {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment();
//设定没10s做一次检查点
env.enableCheckpointing(10000L);
env.execute();
}
}3.1术语解释
检查点分界线(Checkpoint Barrier)
Flink的检查点算法用到了一种称为分界线(barrier)的特殊数据形式,用来把一条流上数据按照不同的检查点分开
插入分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所属的检查点中
而基于分界线之后的数据导致的所有更改,就会被包含在之后的检查点中
//简而言之:barrier本身是一种插入到流中的特殊标记数据,用于标记不同检查点所包含的数据范围3.2检查点算法工作流程
JobManager 会向每个 source 任务发送一条带有新检查点 ID(检查点的批次号) 的消息,通过这种方式来启动检查点
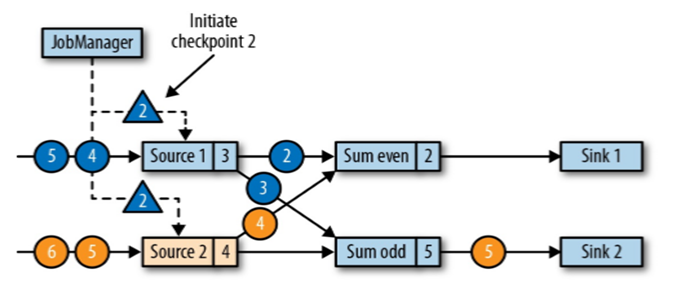
//如图所示:JobManager向两个Source分别发送了第二批检查点启动的命令(蓝色三角符号)- 数据源将它们的状态写入检查点,并发出一个检查点 barrier`
状态后端在状态存入检查点之后,会返回通知给 source 任务,source 任务就会向 JobManager 确认检查点完成
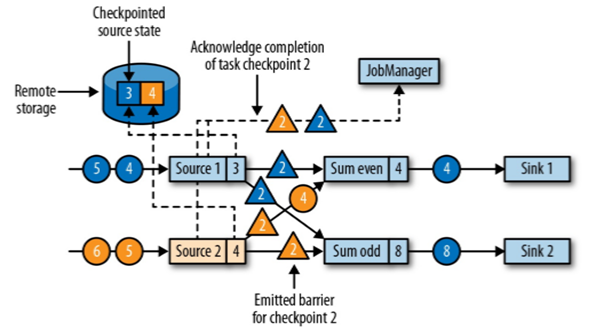
//当source端受到barrier时,会将自己的状态备份,然后往下游SubTask进行广播分界线对齐:barrier 向下游传递,sum 任务会等待所有输入分区的 barrier 到达
对于barrier已经到达的分区,继续到达的数据会被缓存
而barrier尚未到达的分区,数据会被正常处理
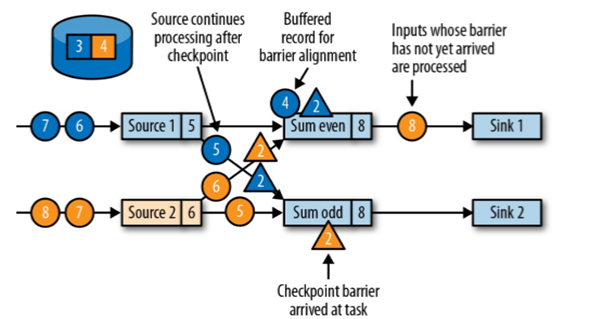
//barrier往下游广播,但是下游必须等待多个上游的barrier全部到齐之后才会触发状态备份 //由于延迟原因,如图,<蓝色三角barrier2>为蓝色数流的barrier,但是在其在达到Sum even之后,(蓝色圆圈4)会先于<橙色三角barrier2>到达,因为SumEven中的barrier没有全部到齐,所以为防止(蓝色圆圈4)参与数据计算,算法会先让其进入缓存,等到barrier全部到齐备份之后再进行计算.(保证Sum even(8),Sum odd(8),备份成功)向下游转发检查点 barrier 后,任务继续正常的数据处理
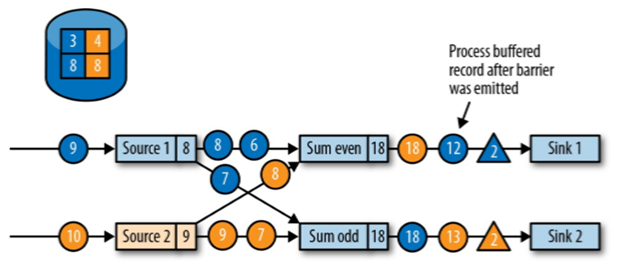
Sink 任务向 JobManager 确认状态保存到 checkpoint 完毕
当所有任务都确认已成功将状态保存到检查点时,检查点就真正完成了
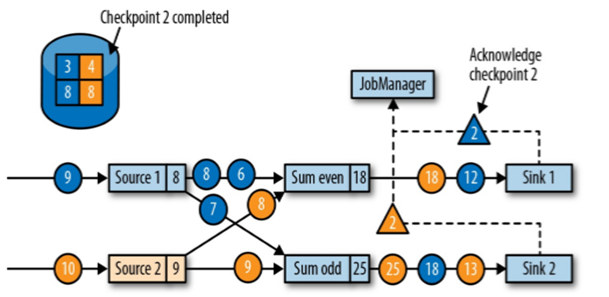
//如何 sink处理完毕后将barrier发送给JobManager表示一个检查点保存成功4.保存点(SavePoints)(实战–0x2)
Flink 还提供了可以自定义的镜像保存功能,就是保存点(savepoints)
原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点
Flink不会自动创建保存点,因此用户(或者外部调度程序)必须明确地触发创建操作
保存点是一个强大的功能。
除了故障恢复外,保存点可以用于:有计划的手动备份,更新应用程序,版本迁移,暂停和重启应用,等等
SavePoint手动存盘
5.如何使用SavePoints
参考:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/ops/state/savepoints.html
0x1 Flink的状态一致性
1.状态一致性概念
有状态的流处理,内部每个算子任务都可以有自己的状态
对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确。
一条数据不应该丢失,也不应该重复计算
在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的。
2.状态一致性分类
2.1 AT-MOST-ONCE(最多一次)
当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重播丢失的数据。At-most-once 语义的含义是最多处理一次事件。
2.2 AT-LEAST-ONCE(至少一次)
在大多数的真实应用场景,我们希望不丢失事件。这种类型的保障称为 at-least-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次。
2.3 EXACTLY-ONCE(精确一次)
恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。
3.一致性检查点(CheckPoint)
Flink 使用了一种轻量级快照机制 —— 检查点(checkpoint)来保证 exactly-once 语义
有状态流应用的一致检查点,其实就是:所有任务的状态,在某个时间点的一份拷贝(一份快照)。而这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候。
//前文提及:检查点的拷贝使用特殊算法进行应用状态的一致检查点,是 Flink 故障恢复机制的==核心==
4.端对端(end-to-end)状态的一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在 Flink 流处理器内部保证的;
而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如 Kafka)和输出到持久化系统
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;
每一个组件都保证了它自己的一致性
整个端到端的一致性级别取决于所有组件中一致性最弱的组件
5.端到端 exactly-once
Flink内部保证:checkpoint
source 端: 可重设数据的读取位置
sink 端 —— 从故障恢复时,数据不会重复写入外部系统,幂等写入,事务写入
5.1幂等写入
所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了
求n次导数依然是不变的
$$
(e^x)^n=e^x
$$
5.2事务写入(Transactional Writes)
事务(Transaction)
应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消
具有原子性:一个事务中的一系列的操作要么全部成功,要么一个都不做
实现思想:构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中
实现方式 ==预写日志== ==两阶段提交==
5.2.1 预写日志(Write-Ahead-Log,WAL)
把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统
简单易于实现,由于数据提前在状态后端中做了缓存,所以无论什么 sink 系统,都能用这种方式一批搞定
DataStream API 提供了一个模板类:GenericWriteAheadSink,来实现这种事务性 sink
**缺点:**降低效率,变成批处理,降低实时性,外部系统没有事务控制,写到一半事务出错
5.2.2 两阶段提交(Two-Phase-Commit,2PC)
对于每个 checkpoint,sink 任务会启动一个事务,并将接下来所有接收的数据添加到事务里
然后将这些数据写入外部 sink 系统,但不提交它们 —— 这时只是“预提交”
当它收到 checkpoint 完成的通知时,它才正式提交事务,实现结果的真正写入
这种方式真正实现了 exactly-once,它需要一个提供事务支持的外部 sink 系统。Flink 提供了 TwoPhaseCommitSinkFunction 接口。
要求
外部 sink 系统必须提供事务支持,或者 sink 任务必须能够模拟外部系统上的事务
在 checkpoint 的间隔期间里,必须能够开启一个事务并接受数据写入
在收到 checkpoint 完成的通知之前,事务必须是“等待提交”的状态。在故障恢复的情况下,这可能需要一些时间。如果这个时候sink系统关闭事务(例如超时了),那么未提交的数据就会丢失
sink 任务必须能够在进程失败后恢复事务
提交事务必须是幂等操作
6.Flink+Kafka 端到端状态一致性的保证
内部 —— 利用 checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
source —— kafka consumer 作为 source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
sink —— kafka producer 作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
7.Exactly-once 两阶段提交
JobManager 协调各个 TaskManager 进行 checkpoint 存储
checkpoint保存在 StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存
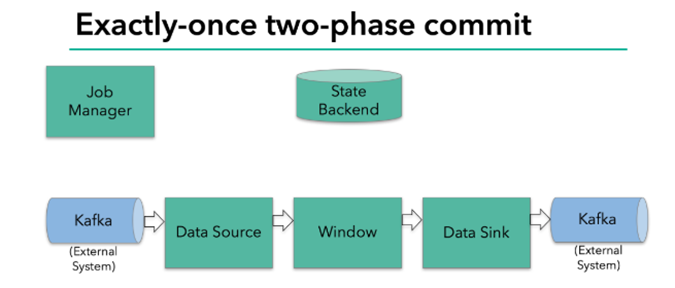
当 checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流
barrier会在算子间传递下去
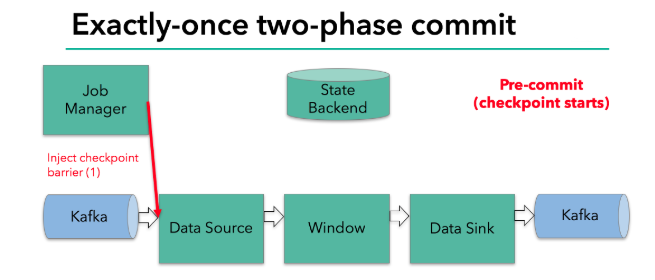
每个算子会对当前的状态做个快照,保存到状态后端
checkpoint 机制可以保证内部的状态一致性
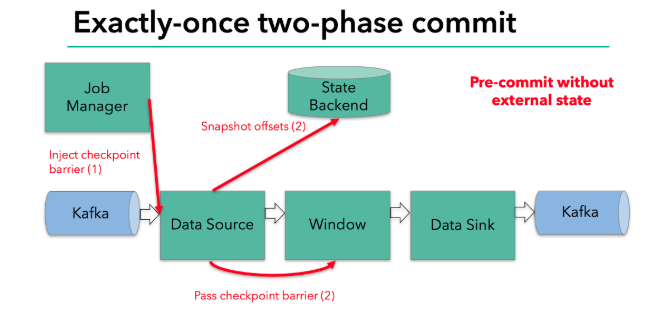
每个内部的 transform 任务遇到 barrier 时,都会把状态存到 checkpoint 里
sink 任务首先把数据写入外部 kafka,这些数据都属于预提交的事务;遇到 barrier 时,把状态保存到状态后端,并开启新的预提交事务
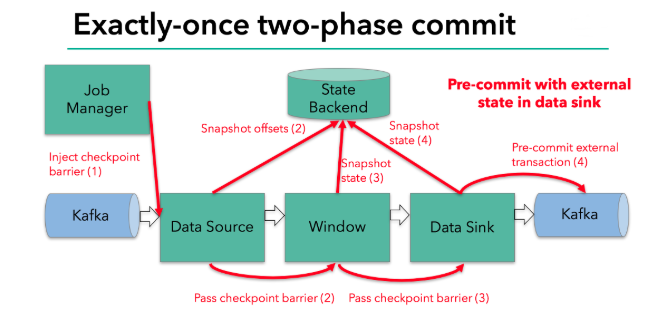
当所有算子任务的快照完成,也就是这次的 checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 checkpoint 完成
sink 任务收到确认通知,正式提交之前的事务,kafka 中未确认数据改为“已确认”
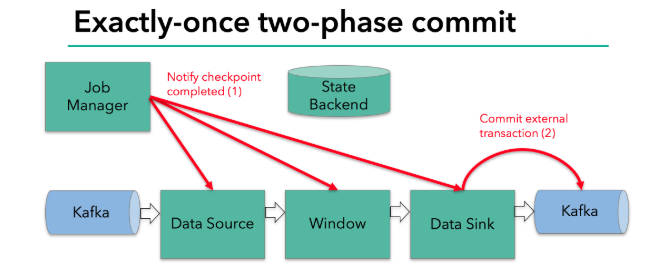
1.//第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”
2.//jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
3.//sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
4.//jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
5.//sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
6.//外部kafka关闭事务,提交的数据可以正常消费了。两阶段提交的网络超时配置问题讨论:
事务的超时时间
checkpoint超时时间
需要将checkpoint的超时时间小于为事务的超时时间
即使checkpoint挂了,事务回滚
8.源码寻找kafka sink的两阶段提交
//API
sensorDS.addSink(
new FlinkKafkaProducer011<String>
("test",
new SimpleStringSchema(),
properties));//source
public class FlinkKafkaProducer011<IN>
extends TwoPhaseCommitSinkFunction<>
//继承两阶段提交//source
public final void notifyCheckpointComplete(long checkpointId) throws Exception {}
//there is exactly one transaction from the latest checkpoint that was triggered and completed. That should be the common case.
//Simply commit that transaction in that case.
//checkPoint完成时调用提交第二步0x2 Flink的SavePoints实操
首先查看配置文件
[user@hadoop]$ cd /opt/moudle/flink/conf/fink-conf.yaml#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
# 支持的文件系统 rockdb可以是一个本地文件系统或者HDFS路径(k-v),基于磁盘
# 效率很高 管理对外内存 使用闪存
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#
# state.backend: filesystem
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
# checkPoint会保存我们的状态,假如我们的任务挂掉,会自己重启,手动kill,checkpoint会自己删掉
# 自己重启会从这里进行读取
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
# Default target directory for savepoints, optional.
# 设置用于手动恢复的savePoint地址
# state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#
# state.backend.incremental: false
# The failover strategy, i.e., how the job computation recovers from task failures.
# Only restart tasks that may have been affected by the task failure, which typically includes
# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.
jobmanager.execution.failover-strategy: regionbin/flink svaepoint jobid hdfs://........
//保存检查点1.State与CK的配置
package com.ecust.checkpoint;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.runtime.state.memory.MemoryStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.io.IOException;
/**
* @author JueQian
* @create 01-19 9:07
*/
public class Flink03_State_Set {
public static void main(String[] args) throws IOException {
//0x0 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//0x1 设置状态后端
env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flink/flinkCk"));
env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop102:8020/flink/flinkCK"));
//0x2 设置CK
env.enableCheckpointing(10000L);
//设置ck模式
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//两次ck时间间隔
env.getCheckpointConfig().setCheckpointInterval(500L);
//设置ck超时时间
env.getCheckpointConfig().setCheckpointTimeout(1000L);
//设置同时最多有多少个CK任务
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//设置两个任务的最小间隔时间 头跟尾
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000L);
//ck重试次数
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(3);
//设置是够倾向于使用checkPoint回复
env.getCheckpointConfig().setPreferCheckpointForRecovery(false);
//0x3 重启策略 固定延迟 重启三次. 5秒重启一次
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.seconds(5)));
//失败率重启策略 每隔50秒内重启3次, 每次与每次之间的间隔3秒
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.minutes(50),Time.seconds(3)));
}
}2.测试案例
计算wordcount
package com.ecust.checkpoint;
import org.apache.commons.collections.map.Flat3Map;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
/**
* @author JueQian
* @create 01-19 9:26
*/
public class Flink04_State_CheckPoint_Test {
public static void main(String[] args) throws Exception {
//0x0 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flink/ck"));
env.enableCheckpointing(5000L);
//设置不自动删除CK
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//0x1 读取端口数据
DataStreamSource<String> socketTextStream = env.socketTextStream("hadoop102", 9999);
//0x2 处理数据
SingleOutputStreamOperator<Tuple2<String, Integer>> process = socketTextStream.process(new MyProcessMap());
SingleOutputStreamOperator<Tuple2<String, Integer>> result = process.keyBy(0).sum(1);
//0x3 打印数据
result.print();
//0x4 执行环境
env.execute();
}
public static class MyProcessMap extends ProcessFunction<String, Tuple2<String,Integer>>{
@Override
public void processElement(String value, Context ctx, Collector<Tuple2<String,Integer>> out) throws Exception {
String[] fields = value.split(",");
for (String field : fields) {
out.collect(new Tuple2<>(field,1));
}
}
}
}3.打包,并上传到集群
1.将外部module依赖排除
2.打包上传flink/jars
4.测试提交任务
bin/flink run \
-m yarn-cluster \
-yqu hive \
-c com.ecust.checkpoint.Flink04_State_CheckPoint_Test \
jars/flink-state-cktest.jar5.将程序中添加UID
package com.ecust.checkpoint;
import org.apache.commons.collections.map.Flat3Map;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
/**
* @author JueQian
* @create 01-19 9:26
*/
public class Flink04_State_CheckPoint_Test {
public static void main(String[] args) throws Exception {
//0x0 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flink/ck"));
env.enableCheckpointing(5000L);
//设置不自动删除CK
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//0x1 读取端口数据
SingleOutputStreamOperator<String> source = env.socketTextStream("hadoop102", 9999).uid("source-1");
//0x2 处理数据
SingleOutputStreamOperator<Tuple2<String, Integer>> process = source.process(new MyProcessMap()).uid("process-2");
SingleOutputStreamOperator<Tuple2<String, Integer>> result = process.keyBy(0).sum(1).uid("sum-3");
//0x3 打印数据
result.print();
//0x4 执行环境
env.execute();
}
public static class MyProcessMap extends ProcessFunction<String, Tuple2<String,Integer>>{
@Override
public void processElement(String value, Context ctx, Collector<Tuple2<String,Integer>> out) throws Exception {
String[] fields = value.split(",");
for (String field : fields) {
out.collect(new Tuple2<>(field,1));
}
}
}
}6.提交UID程序
bin/flink run \
-m yarn-cluster \
-c com.ecust.checkpoint.Flink04_State_CheckPoint_Test \
jars/flink-state-uidtest.jar7.触发savepoint
bin/flink savepoint 1b5e52b1918314b1de6027821a9010ac hdfs://hadoop102:8020/savepoint/ -yid application_1610958550227_0004
# jobid 地址 appid8.使用savepoint重启任务
bin/flink run -s hdfs://hadoop102:8020/savepoint/savepoint-1b5e52-ae6ffd50e8b6 \
-m yarn-cluster \
-yqu hive \
-c com.ecust.checkpoint.Flink04_State_CheckPoint_Test \
./jars/flink-state-uidtest.jar9.修改代码准备升级
package com.ecust.checkpoint;
import org.apache.commons.collections.map.Flat3Map;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
/**
* @author JueQian
* @create 01-19 9:26
*/
public class Flink04_State_CheckPoint_Test {
public static void main(String[] args) throws Exception {
//0x0 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flink/ck"));
env.enableCheckpointing(5000L);
//设置不自动删除CK
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//0x1 读取端口数据
SingleOutputStreamOperator<String> source = env.socketTextStream("hadoop102", 9999).uid("source-1");
//0x2 处理数据
SingleOutputStreamOperator<Tuple2<String, Integer>> process = source.process(new MyProcessMap()).uid("process-2");
SingleOutputStreamOperator<Tuple2<String, Integer>> result0 = process.keyBy(0).sum(1).uid("sum-3");
//0x2 update 升级处理数据
SingleOutputStreamOperator<String> result = (SingleOutputStreamOperator<String>) result0.map(new MapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0 + "总数为:" + stringIntegerTuple2.f1;
}
}).uid("mapper-4");
//0x3 打印数据
result.print();
//0x4 执行环境
env.execute();
}
public static class MyProcessMap extends ProcessFunction<String, Tuple2<String,Integer>>{
@Override
public void processElement(String value, Context ctx, Collector<Tuple2<String,Integer>> out) throws Exception {
String[] fields = value.split(",");
for (String field : fields) {
out.collect(new Tuple2<>(field,1));
}
}
}
}
打包上传
10.从savepoint启动并切换jar包
bin/flink run -s hdfs://hadoop102:8020/savepoint/savepoint-1b5e52-ae6ffd50e8b6 \
-m yarn-cluster \
-c com.ecust.checkpoint.Flink04_State_CheckPoint_Test \
./jars/flink-state-update.jar0x3 Flink的CheckPoint实操
由于我们已经在程序设置好了
注意
bin/flink run -s hdfs://hadoop102:8020/flink/ck/3f3bafadf4fe7dc6ca1dcf9768d71233/chk-346 \
-m yarn-cluster \
-yqu hive \
-c com.ecust.checkpoint.Flink04_State_CheckPoint_Test \
./jars/flink-state-update.jar


