云盘:miaochuanhai@163.com
暗号:大海哥最帅
一 概述
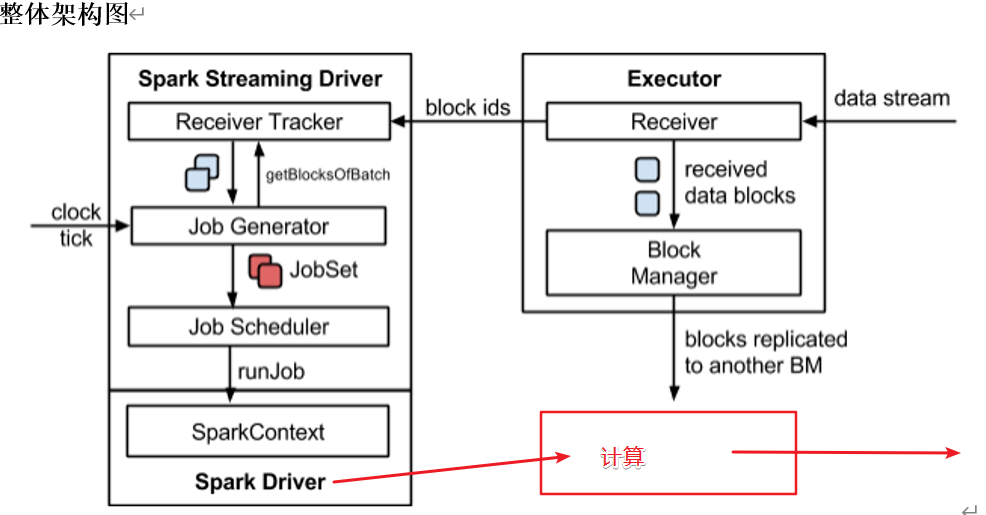
1.Spark架构
2.DStream是什么?
每个时间区间收到的数据作为RDD存在
实时的封装
3.背压机制
可以自动调节receiver的接受速率
通过属性“spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
二 DSteam入门
1.wordCount
需求:使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数
1.1使用netcat作为源头wordcount
object WordCount {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkStreaming")
//初始化配置信息
val ssc = new StreamingContext(sparkConf, Seconds(3))
//接收数据
val line: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//处理
val wordToSumStream: DStream[(String, Int)] = line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
wordToSumStream.print()
ssc.start()
ssc.awaitTermination()
}
}
1.2使用队列源计算wordcount
object queuePractice {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("opt")
val ssc = new StreamingContext(sparkConf, Seconds(3))
//创建RDD队列
val rddQueue = new mutable.Queue[RDD[Int]]()
//创建queueInputDsteam
val value: InputDStream[Int] = ssc.queueStream(rddQueue, oneAtATime = false)
val result: DStream[Int] = value.reduce(_ + _)
//打印结果
result.print()
ssc.start()
for (i <- 1 to 5){
rddQueue += ssc.sparkContext.makeRDD(1 to 5)
Thread.sleep((2000))
}
ssc.awaitTermination()
}
}
2.自定义数据源
2.1自定义数据源receiver
class defReceiver(host:String,port:Int) extends Receiver[String](StorageLevel.MEMORY_ONLY){
override def onStart(): Unit = {
new Thread("Socket Receiver"){
override def run(): Unit = {receive()}
}.start()
}
def receive(): Unit = {
val socket = new Socket(host, port)
//创建一个bufferReader
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8))
//读取数据
var input: String = reader.readLine()
//当receiver没有关闭并且输入数据不为空,则循环发送数据给spark
while(!isStopped()&&input !=null){
store(input)
input= reader.readLine()
}
//如果循环结束,则关闭资源
reader.close()
socket.close()
//重启
restart("restart")
}
override def onStop(): Unit = {}
}2.2自定数据源的使用
object defSource {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("opt")
val ssc = new StreamingContext(sparkConf, Seconds(3))
//创建自动receiver的Streaming
val lineDStream: ReceiverInputDStream[String] = ssc.receiverStream(new defReceiver("hadoop102", 9999))
//将每一行数据做切分,形成一个个单词
val result: DStream[(String, Int)] = lineDStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
result.print()
//启动并且阻塞
ssc.start()
ssc.awaitTermination()
}
}3.kafka数据源
Kafka数据源在SparkStreaming中存在两种API,一种是ReceiverAPI,另一种是DirectAPI
ReceiverAPI已经弃用
DirectAPI:是由计算的Executor来主动消费Kafka的数据,速度由自身控制
3.1kafka的命令行代码
#查看消费topic
bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka -list
#创建kafka的topic
bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --replication-factor 1 --partitions 2 --topic testTopic
#查看Topic详情
bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka \
--describe --topic testTopic
#创建生产者
bin/kafka-console-producer.sh \
--broker-list hadoop102:9092 --topic testTopic
#创建消费者
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic testTopic
#查看_consumer_offsets主题中存储的offset
bin/kafka-consumer-groups.sh --bootstrap-server hadoop102:9092 --describe --group atguiguGroup
#如何查看消费者组的位置3.2使用kafka源来流数据wordcount处理
object SparkStreaming_DirectAuto {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("KakfaSource").setMaster("local[*]")
val scc = new StreamingContext(sparkConf, Seconds(3))
//配置参数,为map
//3.定义Kafka参数:kafka集群地址、消费者组名称、key序列化、value序列化
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguiguGroup",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer]
)
//使用DirectAPI创建DStream
val kafkaToDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(scc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("testTopic"), kafkaPara))
//处理数据
kafkaToDStream.map(record=>record.value())
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
//关闭并堵塞
scc.start()
scc.awaitTermination()
}
}三 DStream转换
DStream上的操作与RDD的类似,分为转换和输出两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。
3.1无状态转换
transfrom()是在Driver端开始执行的
//DStream其实就是内部封装了一个RDD,因此
object SparkStreaming_Transform {
def main(args: Array[String]): Unit = {
//初始化配置
val sparkConf: SparkConf = new SparkConf().setAppName("KakfaSource").setMaster("local[*]")
val scc = new StreamingContext(sparkConf, Seconds(3))
//接受参数
val rDStream: ReceiverInputDStream[String] = scc.socketTextStream("hadoop102", 9999)
//使用transform可以将DStream转换成rdd
println("主程序执行"+Thread.currentThread().getName)//JobGenerator Driver
rDStream.transform(rdd=>{
println("transform执行位置"+Thread.currentThread().getName)
rdd.flatMap(line=>line.split(" ")).map((_,1)).reduceByKey(_+_)}).print()
//关闭并堵塞
scc.start()
scc.awaitTermination()
}
}3.2有状态转换
有状态转化操作:计算当前批次RDD时,需要用到历史RDD的数据。
(1)UpdateStateByKey()
参数中需要传递一个函数,在函数内部根据需求对==当前数据==与==历史数据==进行整合
需求:使用UpdateStateByKey计算WordCount
/**
* @author Jinxin Li
* @create 2020-11-24 18:24
* 通过累积历史状态做的实时的wordcount
*/
object sparkStreaming_updateStateByKey {
def main(args: Array[String]): Unit = {
//这里只会相加key相同的数值,因为是reduce,key相同进来,只要设定value的方法即可
// 定义更新状态方法,参数seq为当前批次单词次数,state为以往批次单词次数
val updateFunc = (seq:Seq[Int],state:Option[Int])=>{
//当前批次
val currentCount = seq.sum
//历史批次
val previousCount = state.getOrElse(0)
//总的数据累加
Some(currentCount+previousCount)
}
val sparkConf: SparkConf = new SparkConf().setAppName("KakfaSource").setMaster("local[*]")
val scc = new StreamingContext(sparkConf, Seconds(3))
scc.checkpoint("./SparkStreaming/ck")//设定存储点,默认的计算与历史相关的都要设定检查点
val reDStream: ReceiverInputDStream[String] = scc.socketTextStream("hadoop102", 9999)
val KvDStream: DStream[(String, Int)] = reDStream.flatMap(_.split(" ")).map((_, 1))
KvDStream.updateStateByKey[Int](
updateFunc,
new HashPartitioner(2)).print()
//关闭并堵塞
scc.start()
scc.awaitTermination()
}
}缺点**
这种UpdateStateByKey在企业中几乎不用,因为存在很多缺点
- 使用checkPoint检查点存储记录历史会产生大量的小文件

- 当前线程关闭后,下次开启重新开始累积
- 即使重新开始累积,但是checkpoint会记录最后一次时间戳,再次启动的时候会把间隔时间的周期再执行一次,容易导致启动卡死
(2)WindowOperations
Window Operations可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Streaming的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
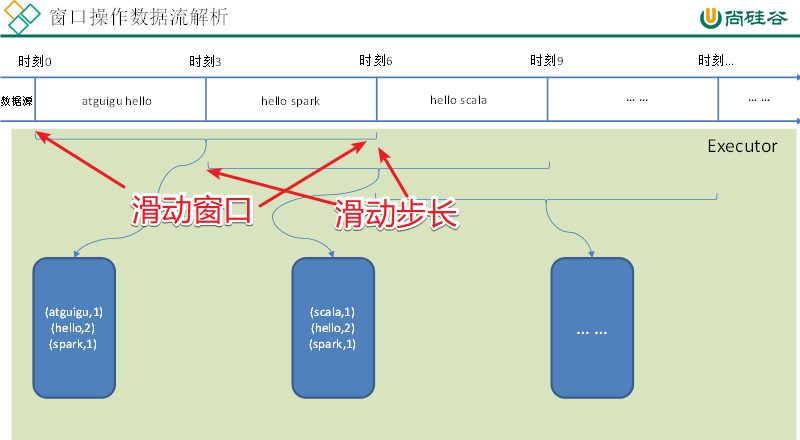
需求
基本语法:window(windowLength, slideInterval): 基于对源DStream窗化的批次进行计算返回一个新的DStream。
需求:统计WordCount:3秒一个批次,窗口12秒,滑步6秒。
object SparkStreaming_window {
def main(args: Array[String]): Unit = {
//这里只会相加key相同的数值,因为是reduce,key相同进来,只要设定value的方法即可
// 定义更新状态方法,参数seq为当前批次单词次数,state为以往批次单词次数
val sparkConf: SparkConf = new SparkConf().setAppName("KakfaSource").setMaster("local[*]")
val scc = new StreamingContext(sparkConf, Seconds(3))
scc.checkpoint("./SparkStreaming/ck")//设定存储点,默认的计算与历史相关的都要设定检查点
val reDStream: ReceiverInputDStream[String] = scc.socketTextStream("hadoop102", 9999)
val lineToTuples: DStream[(String, Int)] = reDStream.flatMap(_.split(" ")).map((_, 1))
//设定窗口,3秒一个批次,窗口持续12秒,步长6秒
val windowDStream: DStream[(String, Int)] = lineToTuples.window(Seconds(12), Seconds(6))
windowDStream.reduceByKey(_+_).print()
//关闭并堵塞
scc.start()
scc.awaitTermination()
}
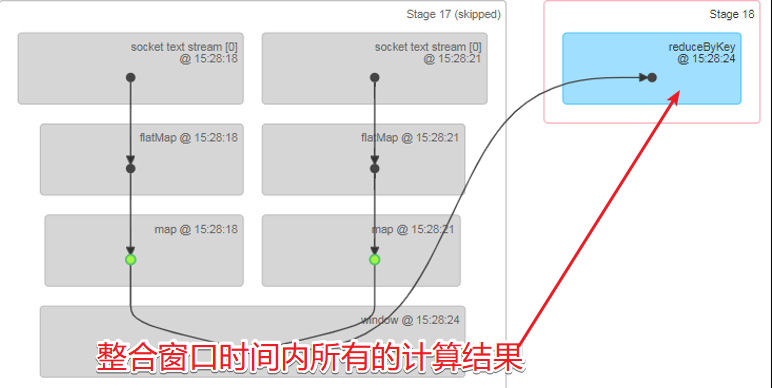
}
(3)reduceByKeyAndWindow
reduceByKeyAndWindow(func, windowLength, slideInterval,[numTasks]):
当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值。
这个是window程序的简化版
object SparkStreaming_reduceByKeyAndWindow {
def main(args: Array[String]): Unit = {
//初始化配置
val sparkConf: SparkConf = new SparkConf().setAppName("KakfaSource").setMaster("local[*]")
val scc = new StreamingContext(sparkConf, Seconds(3))
//接受参数
val line: ReceiverInputDStream[String] = scc.socketTextStream("hadoop102", 9999)
val tuplesDStream: DStream[(String, Int)] = line.flatMap(_.split(" ")).map((_, 1))
tuplesDStream.reduceByKeyAndWindow(
(a:Int,b:Int)=>a+b,//这里要表明类型
Seconds(6),
Seconds(12)
).print()
scc.start()
scc.awaitTermination()
}
}(4)reduceByKeyAndWindow(反向Reduce)
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval,[numTasks])
这个是上一个函数的升级版
通过一个减法,减少统计窗口之间的重复部分
object SparkStreaming_reduceByKeyAndWindow_reduce {
def main(args: Array[String]): Unit = {
//初始化配置
val sparkConf: SparkConf = new SparkConf().setAppName("KakfaSource").setMaster("local[*]")
val scc = new StreamingContext(sparkConf, Seconds(3))
//接受参数
scc.checkpoint("./ck")
val line: ReceiverInputDStream[String] = scc.socketTextStream("hadoop102", 9999)
val tuplesDStream: DStream[(String, Int)] = line.flatMap(_.split(" ")).map((_, 1))
tuplesDStream.reduceByKeyAndWindow(
(a:Int,b:Int)=>a+b,//这里要表明类型
(x:Int,y:Int)=>x-y,
Seconds(12),//这个是窗口间隔
Seconds(6),//这个是滑动距离
new HashPartitioner(2),
(x:(String, Int)) => x._2 > 0//过滤小于0值
).print()
scc.start()
scc.awaitTermination()
}
}3.3其他操作
(1)countByWindow(windowLength, slideInterval): 返回一个滑动窗口计数流中的元素个数;
(2)reduceByWindow(func, windowLength, slideInterval): 通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流;
五 DSteam输出
企业中常用以下方法进行DSteam输出
print():在运行流程序的驱动结点上打印DStream中每一批次数据的最开始10个元素。这用于开发和调试。
foreachRDD(func):这是最通用的输出操作,函数func用于产生DStream的每一个RDD。其中参数传入的函数func应该实现将每一个RDD中数据推送到外部系统,如将RDD存入文件或者写入数据库。
在企业开发中通常采用foreachRDD(),它用来对DStream中的RDD进行任意计算。这和transform()有些类似,都可以让我们访问任意RDD。在foreachRDD()中,可以重用我们在Spark中实现的所有行动操作。比如,常见的用例之一是把数据写到如MySQL的外部数据库中
object SparkStreaming_output {
def main(args: Array[String]): Unit = {
//初始化配置
val sparkConf: SparkConf = new SparkConf().setAppName("KakfaSource").setMaster("local[*]")
val scc = new StreamingContext(sparkConf, Seconds(3))
//接受参数
scc.checkpoint("./ck")
val line: ReceiverInputDStream[String] = scc.socketTextStream("hadoop102", 9999)
val tuplesDStream: DStream[(String, Int)] = line.flatMap(_.split(" ")).map((_, 1))
//tuplesDStream.foreachRDD(rdd=>rdd.collect().foreach(println))
//常规这样输出是一条一条的输出,但是常规不适合这样操作
tuplesDStream.foreachRDD(rdd=>rdd.foreachPartition {
println(Thread.currentThread().getName//需要注意的是,转换输出也是在Driver端执行的
item => item.foreach(println)
})
scc.start()
scc.awaitTermination()
}
}(1)连接不能写在Driver层面(序列化)
(2)如果写在foreach则每个RDD中的每一条数据都创建,得不偿失;
(3)增加foreachPartition,在分区创建(获取)。还是在Driver端进行?
六 优雅的关闭
使用外部文件系统来控制内部程序关闭
使用object
object close2 {
def main(args: Array[String]): Unit = {
val properties = new Properties()
val config = PropertiesUtil.load("config.properties")
val sparkConf: SparkConf = new SparkConf().setAppName("sparkStreaming").setMaster("local[*]")
.set("spark.streaming.stopGracefullyOnShutdown", config.getProperty("spark.streaming.stopGracefullyOnShutdown"))
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lineDStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
lineDStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
new Thread(new StopMonitor(ssc)).start()
//关闭
ssc.start()
ssc.awaitTermination()
}
}关闭object
class StopMonitor(ssc: StreamingContext) extends Runnable{
override def run(): Unit = {
//获得文件系统
val fileSystem: FileSystem = FileSystem.get(new URI("hdfs://hadoop102:8020"), new Configuration(), "atguigu")
//循环监测
while (true){
val bool: Boolean = fileSystem.exists(new Path("hdfs://hadoop102:8020/stopSpark"))
Thread.sleep(5000)
//判断
if (bool){
val state: StreamingContextState = ssc.getState()
if (state==StreamingContextState.ACTIVE){
ssc.stop(stopSparkContext = true,stopGracefully = true)
System.exit(0)
}
}
}
}
}


