SparkSQL_Abstract
什么是Spark SQL
Spark SQL是Spark用于结构化数据(Structured Data) 处理的Spark模块
Spark SQL的底层实现方式是DataFrame API 和 DataSets API
Spark SQL 运行在 Spark Core 之上。它允许开发人员从 Hive 表和 Parquet 文件中导入关系数据,在导入的数据和现有 rdd 上运行 SQL 查询,并轻松地将 rdd 写到 Hive 表或 Parquet 文件中。
Spark SQL 引入了称为 Catalyst 的可扩展优化器,因为它有助于在 Bigdata 支持广泛的数据源和算法。
DataFrame
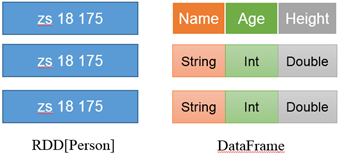
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格
0x0 主要区别
DataFrame也是懒执行的
DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
0x1 DataFrame优势
提供内存管理和执行优化。
自定义内存管理: 这也被称为项目 Tungsten钨。由于数据以二进制格式存储在off-heap memory中,因此节省了大量内存。除此之外,没有垃圾收集开销。
优化执行计划: 这也称为查询优化器。使用这个,可以为查询的执行创建一个优化的执行计划。一旦创建了优化的计划,最终在 Spark 的 RDDs 上执行。
0x2 优化器Catalyst
- Analyze logical plan to solve references 分析逻辑计划以解决引用
- Logical plan optimization 逻辑计划优化
- Physical planning 物理规划
- Code generation to compile part of a query to Java bytecode.把一部分代码转换为字节码文件
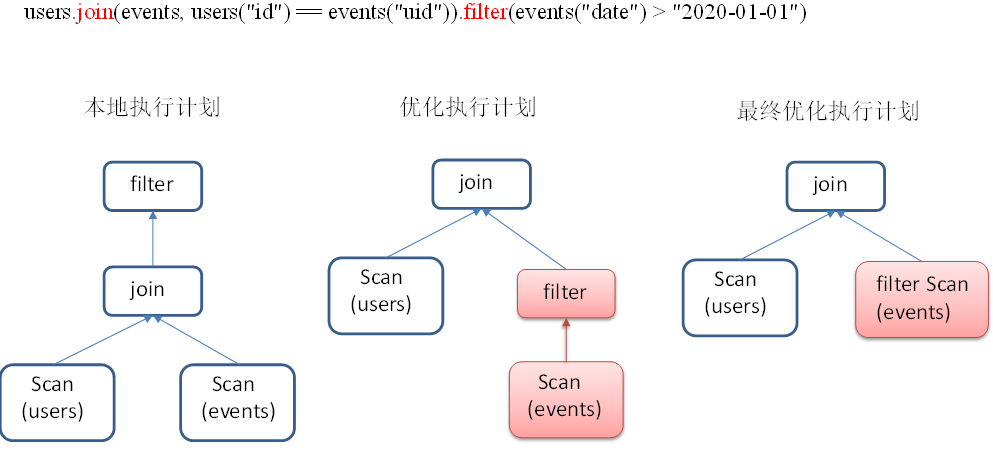
如图所示,底层执行了一些优化策略,举个最简单的例子,两个RDD的数据源想做个连接,连接之后对数据进行过滤,这个时候可能会有产生笛卡尔乘积,而且再数据量大的情况下存在shuffle来说,性能会大大下降,甚至超过内存无法进行计算
DF底层会根据逻辑先进行filter然后再进行join,大大减少了数据量
DataSet
1.6版本后新的抽象
DataSet是分布式数据集合。
DataSet是强类型的。比如可以有DataSet[Car],DataSet[User]。具有类型安全检查
DataFrame是DataSet的特例,type DataFrame = DataSet[Row] ,Row是一个类型,跟Car、User这些的类型一样,所有的表结构信息都用Row来表示。
0x0 为什么是DataSet
DataFrame虽然定义了保存了表结构的原信息
ResultSet rs = pstat.executeQuery("select id,name from user");
while (rs.next()){
rs.getInt(1)//我们知道是id,但是如果我们sql改变顺序,
//比如name,id
//调用结果就得修改
}所以spark就对DataFrame的里面的表结构封装成一个对象,直接使用对象点的方式进行调用,对象的类型就设置为Row类型
DataSet(row) = DataFrame
0x1 Encoder
Encoder编码器是 Spark SQL 中序列化和反序列化(SerDes)框架的基本概念。编码器在对象和 Spark 的内部二进制格式之间进行转换
SparkSession
在老的版本中,SparkSQL提供两种SQL查询起始点:
一个叫SQLContext,用于Spark自己提供的SQL查询;
一个叫HiveContext,用于连接Hive的查询。
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。
SparkSession内部封装了SparkContext,所以计算实际上是由SparkContext完成的。当我们使用spark-shell的时候,Spark框架会自动的创建一个名称叫做Spark的SparkSession,就像我们以前可以自动获取到一个sc来表示SparkContext。
DS-DF-RDD转换
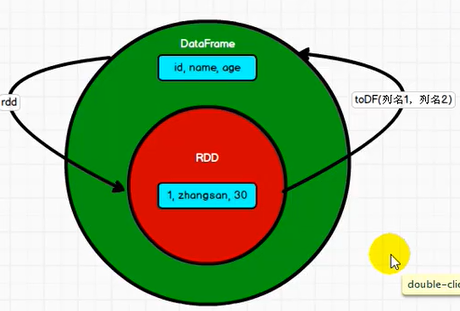

由DataFrame转换过来的RDD的是Row类型
--1.RDD <=> DF
--a. RDD --> DF
rdd.toDF("列名1","列名2",...)
--b. DF --> RDD
df.rdd
--2.RDD <=> DS
--a、RDD --> DS
--将rdd的数据转换为样例类的格式。
rdd.toDS
--这里声明一点
--rdd如果是字符串创建来的,是没有能力toDS的
--这里要实现把对象准备好
val rdd = sc.makeRDD(List(Emp(30,"张三"),Emp(40,"李四"))
rdd.toDS
--这样才能真正的转变
--b. DS --> RDD
ds.rdd
-- 3.DF <=> DS
--a. DF --> DS
df.as[样例类]
--该样例类必须存在,而且df中的数据个样例类对应
--b. DS --> DS
ds.toDF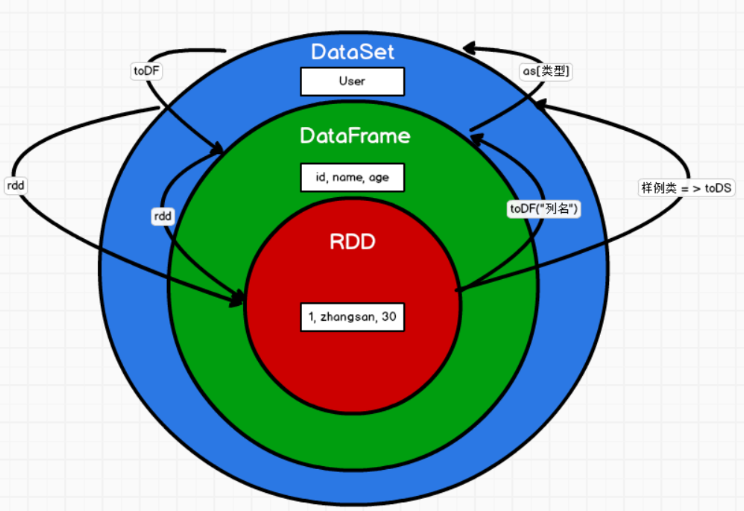
SparkSQL_API
IDEA中使用SparkSQL
0x0添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.5</version>
</dependency>0x1构建sparkSession对象
- 重要:连接SparkSQL
// 1. 创建环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparksql")
// 2. 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()- 添加隐式转换,每次构建完对象以后都需要增加这个 隐式转换的代码
// 3. 增加隐式转换
import spark.implicits._
"1. 这里的spark不是Scala中的包名,而是创建的sparkSession对象的变量名称
2. spark对象不能使用var声明,因为Scala只支持val修饰的对象的引入"
//为什么要导入这个对象的隐式转换呢,为了方便调用 $age等- 说明
-- 为啥要导入隐式转换
sparkSQL是在spark的基础上进行延伸,属于功能的扩展,使用隐式转换,体现了OCP开发原则。
--构建对象为什么不直接new呢?
因为sparkSession是对sparkContext的包装,创建这个对象时,需要很多步骤,将这些过程进行封装,让开发更容易,使用一个构建器来创建对象。0x3代码实现
直接从SparkSQL里看
这里仅仅展示一个示例
git clone git@github.com:fourgold/Spark.gitobject SparkSQL01_DSL {
def main(args: Array[String]): Unit = {
//创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("BASIC")
val sparkSession: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
//DataFrame
val dataFrame: DataFrame = sparkSession.read.json("./input/user.json")
// dataFrame.show()
//DSL语句使用调用方法,类似于Flink总的TABLE API与SQL API
dataFrame.select("name","age").show()
import sparkSession.implicits._
dataFrame.select($"age"+1).as("age").show()
//怎么选择两列
//可以使用单引号代表引用
dataFrame.select('age+1).as("age").show()
//关闭环境
sparkSession.close()
}
}自定义UDF函数
需求:将一个字段的string,加一个前缀
object Demo02_Practice {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().config(new SparkConf().setMaster("local[1]").setAppName("SparkSQL")).getOrCreate()
//用户自定函数
import spark.implicits._
val df: DataFrame = spark.read.json("Day08/input/person.json")
df.createOrReplaceTempView("user")
df.show()
//自定义udf函数
spark.udf.register("addName",(name:String)=>"name:"+name)
spark.sql("select age,addName(username) from user").show()
}
}自定义UDAF函数
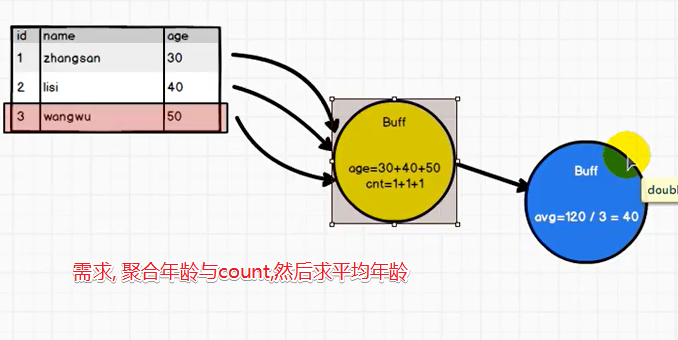
需求:
package com.SparkSql
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, LongType, StructField, StructType}
class MyAvg extends UserDefinedAggregateFunction{
//输入类型
override def inputSchema: StructType = StructType(Array(StructField("age",LongType)))
//缓冲区
override def bufferSchema: StructType =StructType(Array(StructField("sum",LongType),StructField("count",LongType)))
//返回值的数据类型
override def dataType: DataType = DoubleType
//稳定性:对于相同的输入是否一直返回相同的输出。
override def deterministic: Boolean = true
//缓冲区的初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L//sum
buffer(1) = 0L//count
}
// 更新缓冲区中的数据
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// 合并缓冲区
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
override def evaluate(buffer: Row): Any = buffer.getLong(0).toDouble/buffer.getLong(1).toDouble
}聚合函数的使用
//使用
package com.SparkSql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* @author Jinxin Li
* @create 2020-11-03 16:55
*/
object Demo02_Practice {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().config(new SparkConf().setMaster("local[1]").setAppName("SparkSQL")).getOrCreate()
//用户自定函数
import spark.implicits._
val df: DataFrame = spark.read.json("Day08/input/person.json")
df.createOrReplaceTempView("user")
df.show()
//自定义udf函数
spark.udf.register("addName",(name:String)=>"name:"+name)
spark.sql("select age,addName(username) from user").show()
//在spark中注册聚合函数=<<<<<<<<<<<<<<<<<<<<<<<
var MyAvg = new MyAvg
spark.udf.register("avgAge",MyAvg)
spark.sql("select avgAge(age) from user").show()
spark.close()
}
}自定义强类型AggregateUDAF函数
package com.SparkSql
import org.apache.spark.sql.{Encoder, Encoders}
import org.apache.spark.sql.expressions.Aggregator
/**
* @author Jinxin Li
* @create 2020-11-03 19:16
* 求user的平均年龄
* 1.继承
* 2.定义泛型
* In 输入数据类型
* Buf
* out Double输出的数据类型
* 3.重写方法(6)
*/
case class Buff(var total:Long,var count:Long)
class MyAvg2 extends Aggregator[Long,Buff,Double]{
//scala用zero,初始值,零值
//缓冲区的初始化
override def zero: Buff = {
Buff(0L,0L)
}
//根据输入的数据更新缓冲区的数据
override def reduce(b: Buff, a: Long): Buff = {
b.total += a
b.count += 1
b
}
override def merge(b1: Buff, b2: Buff): Buff = {
b1.count += b2.count
b1.total += b2.total
b1
}
override def finish(reduction: Buff): Double = reduction.total.toDouble/reduction.count.toDouble
override def bufferEncoder: Encoder[Buff] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}0x0注册
val MyAvg2 = new MyAvg2
spark.udf.register("avgAge1", functions.udaf(MyAvg2))
spark.sql("select avgAge1(age) from user").show()0x1使用
/**
* 弱类型操作,只有0,1 没有类型的概念
* 没有类型的概念
* 强类型通过属性操作,跟属性没关系
* 自定属性类,定义泛型
*/
object SparkSQL03_UDAF {
def main(args: Array[String]): Unit = {
//创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("BASIC")
val sparkSession: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
//聚合函数也是比较重要的,比如,平均值,最大值,最小值
//DataFrame
val dataFrame: DataFrame = sparkSession.read.json("./input/user.json")
// dataFrame.show()
//将数据创建临时表
dataFrame.createOrReplaceTempView("user")
//view只能查不能改
sparkSession.udf.register("prefixName",(name:String)=>{"name+"+name})
//将某一字段的名字加上前缀
sparkSession.sql(
"""
|select prefixName(name),age from user
|""".stripMargin).show()
//使用udaf-aggregator函数
val myAvg = new MyAvg()
sparkSession.udf.register("myAvg",functions.udaf(new MyAvgAgg))
sparkSession.sql(
"""
|select myAvg(age) as avgAge from user
|""".stripMargin).show()
//关闭环境
sparkSession.close()
}
}SparkSQL_Data
加载数据
如果不指定加载类型,默认的保存与加载类型是parquet
spark.read.load 是加载数据的通用方法
如果读取不同格式的数据,可以对不同的数据格式进行设定
我们前面都是使用 read API 先把文件加载到 DataFrame 然后再查询,其实,我们也可以直接在文件上查询
scala> spark.read.
scala> spark.read.format("…")[.option("…")].load("…")
#format("…"):指定加载的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"。
#load("…"):在"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"格式下需要传入加载数据的路径。
#option("…"):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
#直接在文件上进行查询: 文件格式.`文件路径`
scala> spark.sql("select * from json.`/opt/module/data/user.json`").show 实战:JSON与Parquet文件的读取与保存
spark.read.load()
#默认情况下读取的格式是parquet文件
val df = spark.read.load("/opt/module/spark/examples/src/main/resources/users.parquet")
#格式,例子的地方
#/opt/module/spark/examples/src/main/resources
#保存数据 SparkSQL默认读取或者保存的文件格式parquet
df.write.save("output")
#就想读json文件
val df = spark.read.format("json").load("data/user.json")
#比较简单的json文件
spark.read.json()
#保存json文件
df.write.format("json").save("output1")
#选择表 转换过程由spark自己完成 注意使用飘号
spark.sql("select * from json.`data/user.json`").show保存数据
df.write.save 是保存数据的通用方法
scala>df.write. csv jdbc json orc parquet textFile… … 如果保存不同格式的数据,可以对不同的数据格式进行设定
scala>df.write.
csv jdbc json orc parquet textFile… … 
scala>df.write.format("…")[.option("…")].save("…")
# format("…"):指定保存的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"。
# save ("…"):在"csv"、"orc"、"parquet"和"textFile"格式下需要传入保存数据的路径。
# option("…"):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
# 保存操作可以使用 SaveMode, 用来指明如何处理数据,使用 mode()方法来设置。 有一点很重要: 这些 SaveMode 都是没有加锁的, 也不是原子操作。
#SaveMode 是一个枚举类,其中的常量包括:
#SaveMode.ErrorIfExists(default) "error"(default) 如果文件已经存在则抛出异常
#SaveMode.Append "append" 如果文件已经存在则追加 #SaveMode.Overwrite "overwrite" 如果文件已经存在则覆盖 #SaveMode.Ignore "ignore" 如果文件已经存在则忽略
df.write.mode("append").json("/opt/module/data/output") .save("output")JSON/Parquet/CSV
Parquet
Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式存储格式。
数据源为 Parquet 文件时,Spark SQL 可以方便的执行所有的操作,不需要使用 format。
修改配置项 spark.sql.sources.default,可修改默认数据源格式。
scala> val df = spark.read.load("examples/src/main/resources/users.parquet")
scala> df.show
scala> var df = spark.read.json("/opt/module/data/input/people.json")
#保存为 parquet 格式
scala> df.write.mode("append").save("/opt/module/data/output")JSON
Spark SQL 能够自动推测 JSON 数据集的结构,并将它加载为一个 Dataset[Row]. 可以通过 SparkSession.read.json()去加载 JSON 文件。
#将读取的文件保存
val df = spark.read.json("data/user.json")
#保存 因为保存模式的原因,再次保存会报错
df.write.format("json").save("output")注意:Spark 读取的 JSON 文件不是传统的 JSON 文件,每一行都应该是一个 JSON 串。格式如下:
{"name":"Michael"}
{"name":"Andy", "age":30}
[{"name":"Justin", "age":19},{"name":"Justin", "age":19}]
#因为Spark读取是一行一行读的,所以一行应该是一个标准的json文件CSV
Spark SQL 可以配置 CSV 文件的列表信息,读取 CSV 文件,CSV 文件的第一行设置为数据列 spark
#option例子是分号 optipn-分隔符 header-表头 inferSchema-??
spark.read.format("csv").option("sep", ";").option("inferSchema", "true").option("header", "true").load("data/user.csv") HIVE
Apache Hive 是 Hadoop 上的 SQL 引擎,Spark SQL 编译时可以包含 Hive 支持,也可以不包含。
包含 Hive 支持的 Spark SQL 可以支持 Hive 表访问、UDF (用户自定义函数)以及 Hive 查询语言(HiveQL/HQL)等。
SparkSQL想连接HIVE有两种连接方式
内置Hive
SparkSQL本身也具有元数据,数据仓库,全部都有,通过内置Hive实现
#显示全部表
spark.sql("show tables").show发现内部文件系统自动生成了metadb
# 导入数据
val df = spark.read.json("data/user.json")
# 创建表
spark.sql("create table test(age int)")
#查看表
spark.sql("show tables").show
#加载数据
spark.sql("load data local inpath 'data/user.text' into table test")
外置Hive
一般使用外置Hive如果想连接外部已经部署好的 Hive,需要通过以下几个步骤:
- Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
- 把 Mysql 的驱动 copy 到 jars/目录下
- 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
- 重启 spark-shell
然后查看一下数据库
已经连接到Hive了
Beeline
bin/spark-sql
#为什么带有(default)
Spark Thrift Server 是 Spark 社区基于 HiveServer2 实现的一个 Thrift 服务。旨在无缝兼容HiveServer2。
因为 Spark Thrift Server 的接口和协议都和 HiveServer2 完全一致,因此我们部署好 Spark Thrift Server 后,可以直接使用 hive 的 beeline 访问 Spark Thrift Server 执行相关语句。
Spark Thrift Server 的目的也只是取代 HiveServer2,因此它依旧可以和 Hive Metastore进行交互,获取到 hive 的元数据。
如果想连接 Thrift Server,需要通过以下几个步骤:
Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
把 Mysql 的驱动 copy 到 jars/目录下
如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
启动 Thrift Server
beeline客户端连接
sbin/start-thriftserver.sh
# 使用 beeline 连接 Thrift Server
bin/beeline -u jdbc:hive2://linux1:10000 -n root 代码操作
#注意:在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址:
config("spark.sql.warehouse.dir", "hdfs://linux1:8020/user/hive/warehouse") 权限问题
System.setProperty("HADOOP_USER_NAME", "root")


