0x1 spark概述
1.历史
在之前的学习中,Hadoop的MapReduce是大家广为熟知的计算框架,那为什么咱们还要学习新的计算框架Spark呢,这里就不得不提到Spark和Hadoop的关系。
首先从时间节点上来看:
Hadoop
- 2006年1月,Doug Cutting加入Yahoo,领导Hadoop的开发
- 2008年1月,Hadoop成为Apache顶级项目
- 2011年1.0正式发布
- 2012年3月稳定版发布
- 2013年10月发布2.X (Yarn)版本
Spark
- 2009年,Spark诞生于伯克利大学的AMPLab实验室
- 2010年,伯克利大学正式开源了Spark项目
- 2013年6月,Spark成为了Apache基金会下的项目
- 2014年2月,Spark以飞快的速度成为了Apache的顶级项目
- 2015年至今,Spark变得愈发火爆,大量的国内公司开始重点部署或者使用Spark
2.Spark核心模块

Spark Core
Spark Core中提供了Spark最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib都是在Spark Core的基础上进行扩展的
Spark SQL
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
Spark Streaming
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
Spark MLlib
MLlib是Spark提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
Spark GraphX
GraphX是Spark面向图计算提供的框架与算法库。
3.入门wordCount
object wordCountTest {
def main(args: Array[String]): Unit = {
//spark标准获取流程
val sparkConf: SparkConf = new SparkConf().setAppName("wordCount").setMaster("local[1]")
val sc = new SparkContext(sparkConf)
//创建RDD,使用textFile的方式创建RDD
val line: RDD[String] = sc.textFile("./word.txt", 1)
val result: RDD[(String, Int)] = line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
//打印
result.collect().foreach(println)
sc.close()
}
}4.spark运行模式
| Spark运行环境 | 用法 |
|---|---|
| Local模式 | 测试 |
| Standalone模式 | 独立部署Matser-Worker 自身提供计算资源,降低了耦合性 |
| Yarn模式 | 提供集群模式 |
| K8S模式 | |
| Mesos模式 | |
| Windows模式 |
5.spark端口号
| Spark端口号 | 详解 | Hadoop |
|---|---|---|
| 内部通信:==7077== | Spark Master内部通信服务端口号 | 8020/9000 |
| Master资源监控:8080/改==8989== | Standalone模式下,Spark Master Web端口号 | 9870 |
| Spark-Shell监控:==4040== | Spark查看当前Spark-shell运行任务情况端口号 | |
| Spark使用HDFS端口:==8020== | ||
| 历史服务器UI端口:==18080== | Spark历史服务器端口号 | 19888 |
| Yarn:==8088== | Hadoop YARN任务运行情况查看端口号 | 8088 |
6.Spark运行组件
Spark框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
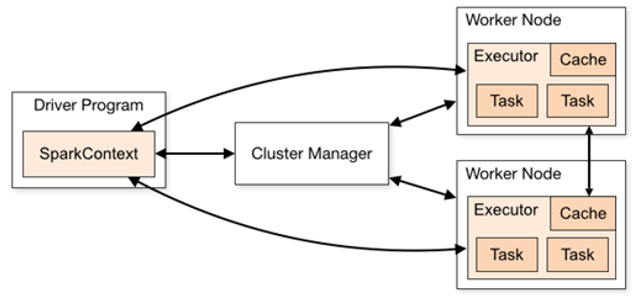
6.1Spark Executor
集群中运行在==工作节点(Worker)中的一个JVM进程==,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点Executor的内存大小和使用的虚拟CPU核(Core)数量。
| 名称 | 说明 |
|---|---|
| –num-executors | 配置Executor的数量 |
| –executor-memory | 配置每个Executor的内存大小 |
| –executor-cores | 配置每个Executor的虚拟CPU core数量 |
| Executor如果是3核,设备是单核,模拟的多线程操作,其实是并发操作 |
6.2并行与并发
我们会给Executor分配虚拟的核心数量,如果核心不够会触发多线程操作,并发
如果核心够用,则进行并行操作,可以进行配置
6.3有向无环图
表示一种依赖关系,依赖关系形成的拓扑图形称为DAG,有向无环图
graph LR A-->B B-->C B-->D D--禁止-->A
如图,D向A会形成无环图,有环会形成死循环(与maven类似)
7.Yarn Cluster任务提交流程
核心:分两大块 1.资源的申请 2.计算的准备 任务发给资源
Client与Cluster区别在于Driver程序运行的节点位置
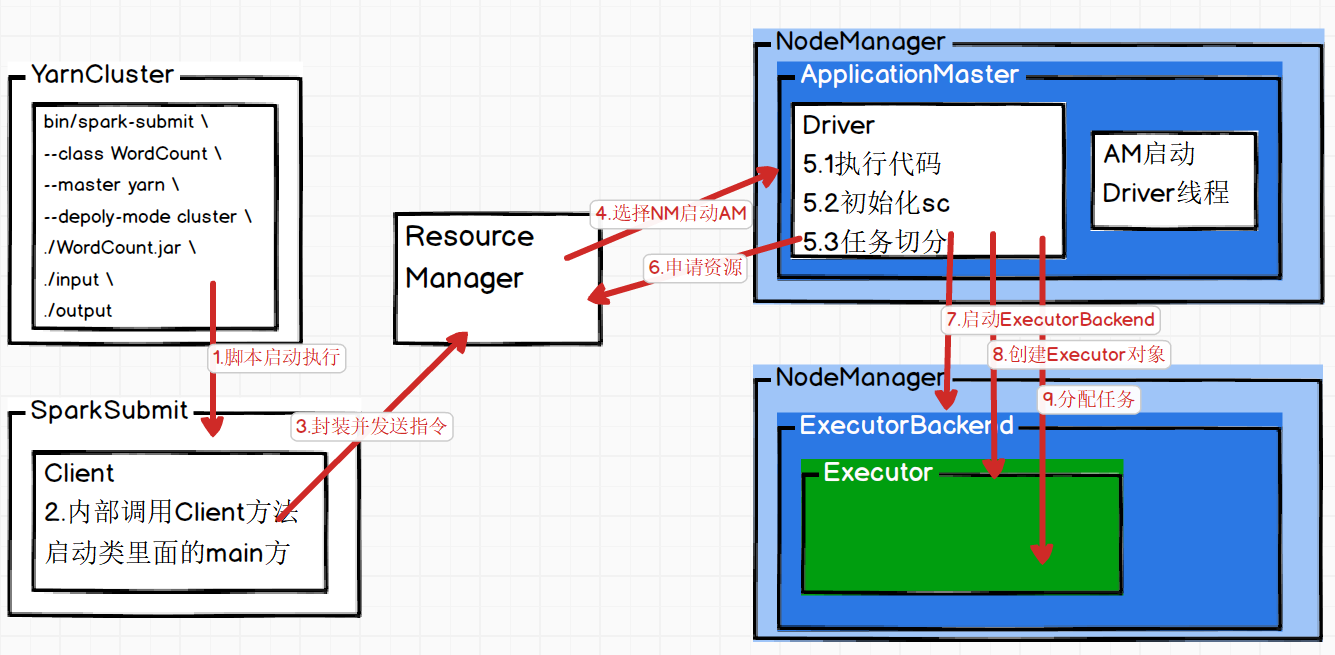
- 任务提交
- 向ResourceManager通讯申请启动ApplicationMaster
- ApplicationMaster选择合适的节点借用NodeManager启动一个container
- 在container中运行AppMatser=Driver
- Driver启动后,向RM申请container运行Executor进程
- Executor进程启动后反向向Driver进行注册
- 全部注册完成后开始执行main函数
- 执行到action算子,触发一个job,根据是否发生shuffle开始划分stage
- 每个stage生成对应的TaskSet[task1,task2,task3…]
- 然后将task分发到各个Executor上执行
[shenneng@hadoop102 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
100x2 Spark框架
Spark和Hadoop的根本差异是多个作业之间的数据通信问题
| Spark运行环境 | 用法 |
|---|---|
| Local模式 | 测试 |
| Standalone模式 | 独立部署Matser-Worker 自身提供计算资源,降低了耦合性 |
| Yarn模式 | 提供集群模式 |
| K8S模式 | |
| Mesos模式 | |
| Windows模式 |
1.Yarn模式
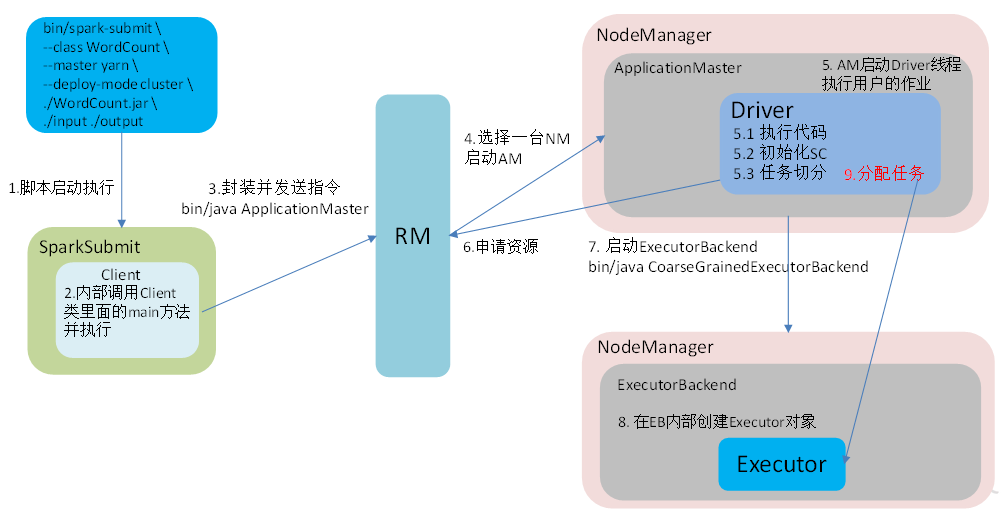
Client与Cluster的主要区别是Driver是否在本地运行
2.分布式计算模拟
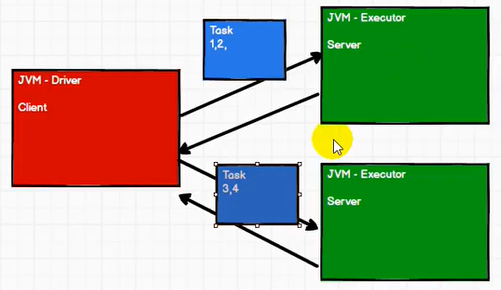
通过简单的分布式计算模拟,理解任务的拆分,运行的模块,并行的原理,RDD的封装,底层数据结构
DRIVER
//DRIVER
package com.ecust.saprkcore
import java.io.{ObjectOutputStream, OutputStream}
import java.net.{ServerSocket, Socket}
/**
* @author Jinxin Li
* @create 2020-12-31 13:43
*/
object Driver {
def main(args: Array[String]): Unit = {
//进行逻辑的封装,计算的准备,数据的提交
val client1 = new Socket("localhost", 9999)
val client2 = new Socket("localhost", 8888)
val out1: OutputStream = client1.getOutputStream
val out2: OutputStream = client2.getOutputStream
val objOut1 = new ObjectOutputStream(out1)
val objOut2 = new ObjectOutputStream(out2)
val task = new Task()
val subTask1 = new SubTask()
subTask1.logic=task.logic
subTask1.data=task.data.take(2)
val subTask2 = new SubTask()
subTask2.logic=task.logic
subTask2.data=task.data.takeRight(2)
objOut1.writeObject(subTask1)
objOut1.flush()
objOut1.close()
objOut2.writeObject(subTask2)
objOut2.flush()
objOut2.close()
//发送,注意在网络中传递的数据要进行序列化,不可能传递对象,必须序列化
println("任务发送完毕")
//关闭客户端
client1.close()
client2.close()
}
}EXECUTOR1
object Executor1 {
def main(args: Array[String]): Unit = {
//启动服务器,接受数据
val server = new ServerSocket(9999)
println("服务器9999启动,等待接受数据...")
val client: Socket = server.accept()
val in: InputStream = client.getInputStream
val objIn = new ObjectInputStream(in)
val task = objIn.readObject().asInstanceOf[SubTask]
val ints: List[Int] = task.compute()
println("接收到客户端9999接受的数据:"+ints)
objIn.close()
client.close()
server.close()
}
}EXECUTOR2
object Executor2 {
def main(args: Array[String]): Unit = {
//启动服务器,接受数据
val server = new ServerSocket(8888)
println("服务器9999启动,等待接受数据...")
val client: Socket = server.accept()
val in: InputStream = client.getInputStream
val objIn = new ObjectInputStream(in)
val task= objIn.readObject().asInstanceOf[SubTask]
val ints: List[Int] = task.compute()
println("接收到客户端8888接受的数据:"+ints)
objIn.close()
client.close()
server.close()
}
}SUBTASK
class SubTask extends Serializable {
//这是一种特殊的数据结构,其中包含了数据的格式,数据的计算逻辑与算子转换
//接收到数据之后,可以进行计算
//RDD 广播变量 累加器 就是类似的数据结构
var data :List[Int] = _
var logic:Int=>Int = _
//计算任务
def compute() ={
data.map(logic)
}
}TASK
class Task extends Serializable {//实现序列化 特质
//包含原数据的数据结构
val data = List(1, 2, 3, 4)
val function: Int => Int = (num: Int) => {
num * 2
}
//注意函数的类型是Int=>Int
val logic:Int=>Int = _*2
//计算任务
def compute() ={
data.map(logic)
}
}3.RDD与IO
字节流&字符流
InputStream in = new FileInputStream("path")
int i = -1
while(i = in.read()!=-1){
println(i)
}graph LR File-->FileInputStream--read-->console
缓冲流
InputStream in = new BufferedInputStream(new FileInputStream("path"))
int i = -1
while(i = in.read()!=-1){
println(i)
}graph LR File-->FileInputStream-->BufferedInputStream--read-->console

转换流InputStreamReader
Reader in = new BufferedReader(
new InputStreamReader(
new FileInputStream("path"),
"UTF-8"
)
)
String s = null
while((s=in.readLine())!=null){
println(i);
)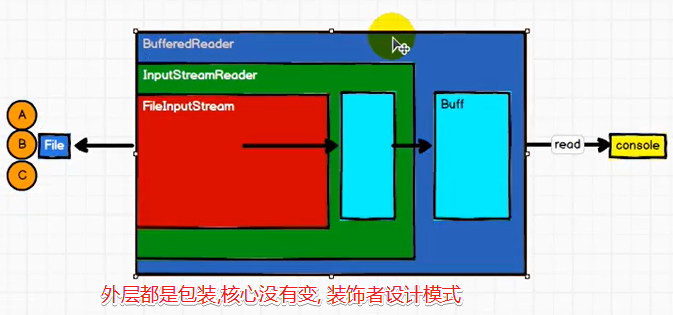
可以看出核心是FileInputFormat,转换流与缓冲流都是包装,这种设计模式成为装饰者设计模式
哪些inputformat,都是对读取逻辑的封装,没有真正的读取数据
readLine才会真正的执行,new的过程仅仅是建立连接,但是没有真正的读取,有种延迟加载的感觉
RDD的组装方式,与IO的封装也是非常的类似
new HadoopRDD//textFile
new MapPartitionsRDD()//flatMap
new MapPartitionsRDD()//map
new ShuffleRDD()//reduceByKey
//执行
rdd.collect()一层一层的包装

RDD的数据处理方式类似于IO流,也有装饰者设计模式
RDD的数据只有在调用collect方法时,才会真正的执行
RDD是不保存数据的,但是IO可以临时保存一部分数据
4. 分区
RDD是一个最基本的数据处理模型
类似于Kafka中的分区,我们将数据进行分区,分区之后分成不成的Task,可以分发至Executor进行计算
RDD是最小的数据处理单元,里面包含了分区信息,提高并行计算的能力
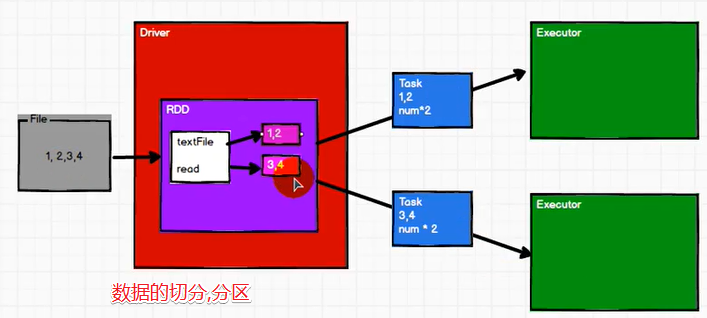
0x3 spark核心
1. spark核心三大数据结构
RDD : 弹性分布式数据集
累加器:分布式共享只写变量
广播变量:分布式共享只读变量
2.RDD基本概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
1.弹性
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
2.分布式:数据存储在大数据集群不同节点上
3.数据集:RDD封装了计算逻辑,并不保存数据
4.数据抽象:RDD是一个抽象类,需要子类具体实现
5.不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑
6.可分区、并行计算
3.RDD核心属性
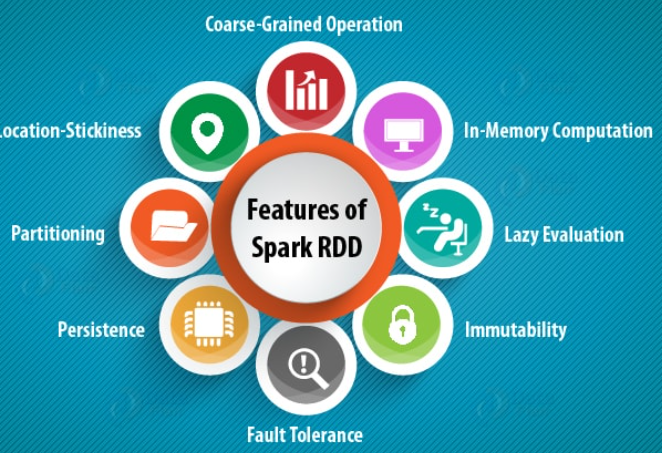
图:Spark RDD核心属性
粗粒度操作(无法对单个元素进行操作)
内存中计算
懒执行
不变性
容错性
持久性(cache可以选择等级与checkpoint)
--数据缓存 wordToOneRdd.cache() --可以更改存储级别 mapRdd.persist(StorageLevel.MEMORY_AND_DISK_2) --设置检查点路径 sc.setCheckpointDir("./checkpoint1") --数据检查点:针对wordToOneRdd做检查点计算 wordToOneRdd.checkpoint() --一般两者联合使用可分区(分区列表)
粘度分区(自定分区)
4.RDD缺点
- 没有内置的优化引擎,RDD无法利用Spark的高级优化器(包括catalyst optimizer与Tungsten执行引擎)的优势。开发人员需要根据其属性优化每个RDD
- 只能处理结构化数据与DataFrame和数据集不同,RDD不会推断所摄取数据的模式,而是需要用户指定它。
- 性能限制,作为内存中的JVM对象,RDD涉及垃圾收集和Java序列化的开销,这在数据增长时非常昂贵。
- 没有足够的内存来存储RDD时,它们会拖慢运行速度。也可以将RDD的该分区存储在不适合RAM的磁盘上。结果,它将提供与当前数据并行系统类似的性能。
5.RDD的来源
- 使用集合创建parallelize MakeRDD
- 外部存储文件创建RDD textfile
- 从其他RDD创建(血缘关系,cache,checkpoint)
- 直接创建RDD 内部使用
6.RDD的==分区分片问题==
RDD分区意味着一个分区一个job么,
RDD分区3意味着要在三个executor里执行么
重新分区,加入三个executor在不同的container里是如何发生shuffle里的,还是三个分区是一个job,这一个job在一个container里执行
7.RDD的序列化
从计算的角度, 算子以外的代码都是在Driver端执行, 算子里面的代码都是在Executor端执行。
那么在scala的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给Executor端执行,就会发生错误
所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。Scala2.12版本后闭包编译方式发生了改变
Kryo序列化框架
Spark2.0开始支持另外一种Kryo序列化机制。Kryo速度是Serializable的10倍。当RDD在Shuffle数据的时候,简单数据类型、数组和字符串类型已经在Spark内部使用Kryo来序列化。
即使使用Kryo序列化,也要继承Serializable接口
8.RDD依赖与血缘
8.1概述
RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
相邻的两个RDD之间的关系称为依赖关系
多个连续的RDD的依赖关系,称之为血缘关系
我们的每一个RDD都会保存我们的血缘关系,会保存之前的血缘关系
RDD为了提供容错性,需要将RDD间的关系保存下来,一旦出现错误,可以根据血缘关系将数据源重新计算
val rdd1 = rdd.map(_.2)
//新的RDD依赖于旧的RDDgraph LR RDD1--依赖-->RDD2--依赖-->RDD3--依赖-->RDD4 RDD4--flatmap-->RDD3 RDD3--map-->RDD2 RDD2--reduceByKey-->RDD1
8.2血缘关系的查看
//血缘关系的演示
//每个RDD记录了以前所有的血缘关系
package com.test
import org.apache.spark.api.java.JavaSparkContext.fromSparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Jinxin Li
* @create 2020-10-26 10:04
*/
object wordCount {
def main(args: Array[String]): Unit = {
val config: SparkConf = new SparkConf().setAppName("MyWordCount").setMaster("local[*]")
val sc = new SparkContext(config)
val lines: RDD[String] = sc.textFile("./word.txt")
println("++++++++++++++++++++++++++++++++++=")
println(lines.toDebugString)//打印血缘关系
val words: RDD[String] = lines.flatMap(_.split(" "))
println("++++++++++++++++++++++++++++++++++=")
println(words.toDebugString)
val pairs: RDD[(String, Int)] = words.map((_, 1))
println("++++++++++++++++++++++++++++++++++=")
println(pairs.toDebugString)
val word: RDD[(String, Int)] = pairs.reduceByKey(_ + _)
println("++++++++++++++++++++++++++++++++++=")
println(word.toDebugString)
println("++++++++++++++++++++++++++++++++++=")
word.collect().foreach(println(_))
sc.close;
}
}++++++++++++++++++++++++++++++++++=
(2) ./word.txt MapPartitionsRDD[1] at textFile at wordCount.scala:15 []
| ./word.txt HadoopRDD[0] at textFile at wordCount.scala:15 []
++++++++++++++++++++++++++++++++++=
(2) MapPartitionsRDD[2] at flatMap at wordCount.scala:18 []
| ./word.txt MapPartitionsRDD[1] at textFile at wordCount.scala:15 []
| ./word.txt HadoopRDD[0] at textFile at wordCount.scala:15 []
++++++++++++++++++++++++++++++++++=
(2) MapPartitionsRDD[3] at map at wordCount.scala:21 []
| MapPartitionsRDD[2] at flatMap at wordCount.scala:18 []
| ./word.txt MapPartitionsRDD[1] at textFile at wordCount.scala:15 []
| ./word.txt HadoopRDD[0] at textFile at wordCount.scala:15 []
++++++++++++++++++++++++++++++++++=
(2) ShuffledRDD[4] at reduceByKey at wordCount.scala:24 []
//这个地方断开,表示shuffle +-
+-(2) MapPartitionsRDD[3] at map at wordCount.scala:21 []
| MapPartitionsRDD[2] at flatMap at wordCount.scala:18 []
| ./word.txt MapPartitionsRDD[1] at textFile at wordCount.scala:15 []
| ./word.txt HadoopRDD[0] at textFile at wordCount.scala:15 []
++++++++++++++++++++++++++++++++++=可以看出每个RDD会存储所有的血缘关系
同时使用dependices可以查看依赖关系
object wordCount {
def main(args: Array[String]): Unit = {
val config: SparkConf = new SparkConf().setAppName("MyWordCount").setMaster("local[*]")
val sc = new SparkContext(config)
val lines: RDD[String] = sc.textFile("./word.txt")
println("++++++++++++++++++++++++++++++++++=")
println(lines.dependencies)
val words: RDD[String] = lines.flatMap(_.split(" "))
println("++++++++++++++++++++++++++++++++++=")
println(words.dependencies)
val pairs: RDD[(String, Int)] = words.map((_, 1))
println("++++++++++++++++++++++++++++++++++=")
println(pairs.dependencies)
val word: RDD[(String, Int)] = pairs.reduceByKey(_ + _)
println("++++++++++++++++++++++++++++++++++=")
println(word.dependencies)
println("++++++++++++++++++++++++++++++++++=")
word.collect().foreach(println(_))
sc.close;
}
}++++++++++++++++++++++++++++++++++=
List(org.apache.spark.OneToOneDependency@1a2bcd56)
++++++++++++++++++++++++++++++++++=
List(org.apache.spark.OneToOneDependency@3c3a0032)
++++++++++++++++++++++++++++++++++=
List(org.apache.spark.OneToOneDependency@5e519ad3)
++++++++++++++++++++++++++++++++++=
List(org.apache.spark.ShuffleDependency@765d55d5)
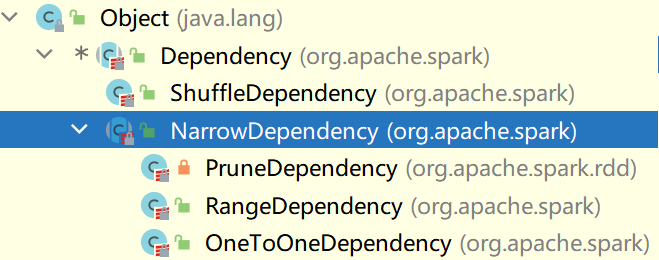
++++++++++++++++++++++++++++++++++=可以看出存在两种依赖关系,一种OneToOneDependency与ShuffleDependency
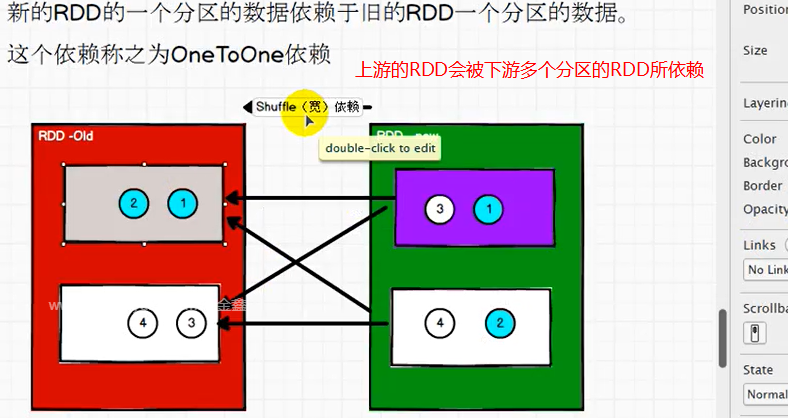
新的RDD的一个分区的数据依赖于旧的RDD的一个分区的数据,这种依赖称之为OneToOne依赖
新的RDD的一个分区的数据依赖于旧的RDD的多个分区的数据,这种依赖称为Shuffle依赖(数据被打乱重新组合)
源码中的依赖关系
8.3阶段划分与源码
Shuffle划分阶段
如果是oneToOne不需要划分阶段
不同的阶段要保证Task执行完毕才能执行下一个阶段
阶段的数量等于shuffle依赖的数量+1
collect
dagScheduler.runjob
val waiter = submitJob//DAGScheduler-681
//让下翻
override def run(): Unit = eventProcessLoop.post(JobSubmitted)//DAGScheduler-714
private[scheduler] def handleJobSubmitted//DAGScheduler-975
{
var finalStage: ResultStage = null//判定finalStage是否存在 985
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)//如果不存在则创建一个空的ResultStage 986
}
//也就是说ResultStage只有一个
private def createResultStage:ResultStage = {
//445
val parents = getOrCreateParentStages(rdd, jobId)//有没有上一个阶段,这个rdd是当前的reduceBykey最后的rdd
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stage
}
/**获得父阶段列表*/
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {//466
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)//一个shuffle就会转换为一个阶段
}.toList
}
private[scheduler] def getShuffleDependencies(//508
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new ListBuffer[RDD[_]]
waitingForVisit += rdd//放入当前rdd reduceByKey的rdd
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.remove(0)
if (!visited(toVisit)) {//判断之前是否访问过
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep//模式匹配判断是否是shuffle依赖
case dependency =>
waitingForVisit.prepend(dependency.rdd)
}
}
}
parents
}
private def getOrCreateShuffleMapStage( //338
... ShuffleMapStage = {...
createShuffleMapStage(shuffleDep, firstJobId)
}
def createShuffleMapStage[K, V, C](//384
... ShuffleMapStage = {
val rdd = shuffleDep.rdd
...
val numTasks = rdd.partitions.length
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ShuffleMapStage()
...
stage
}8.4RDD的任务划分
行动算子底层是runJob
Application:初始化一个SparkContext即生成一个Application
Job:一个Action算子就会生成一个Job
Stage:Stage等于宽依赖(ShuffleDependency)+1
Task:一个Stage阶段中,最后一个RDD分区个数就是Task的个数
注意:Application->Job->Stage->Task每一层都是一对n的关系
提交过程是一个阶段一个阶段的提交
private def submitStage(stage: Stage): Unit = {//1084
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug(s"submitStage($stage (name=${stage.name};" +
s"jobs=${stage.jobIds.toSeq.sorted.mkString(",")}))")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)//有没有上一级阶段
logDebug("missing: " + missing)
if (missing.isEmpty) {//如果没有上一级的stage,则为空
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)//为空就提交stage/tasks
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
val tasks: Seq[Task[_]] = try {//1217
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {//匹配的阶段类型
case stage: ShuffleMapStage =>//shuffleMaptask
//new 几个跟map相关,ShuffleMapStage
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>//计算分区
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>//这里面有多少元素
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)//到底有多个new
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
}
//计算分区
// Figure out the indexes of partition ids to compute.
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions(){}
//ResultStage 61
override def findMissingPartitions(): Seq[Int] = {
val job = activeJob.get
(0 until job.numPartitions).filter(id => !job.finished(id))
}//此处的job.numPartitions就是最后一个RDD的分区
//三个分区就是0-3
//一个RDD的三个分区,从并行角度就会分配为3个Task
//SuffleMapStage 91
override def findMissingPartitions(): Seq[Int] = {
mapOutputTrackerMaster
.findMissingPartitions(shuffleDep.shuffleId)
.getOrElse(0 until numPartitions)
}
}一个应用程序会对应多个job(一个行动算子算是一个job)
ShuffleMapStage=>ShuffleMapTask
ResultStage=>ResultTask
9.RDD分区器
- Hash分区(默认)
- Range分区
- 自定义分区
只有Key-Value类型的RDD才有分区器,非Key-Value类型的RDD分区的值是None
每个RDD的分区ID范围:0 ~ (numPartitions - 1),决定这个值是属于那个分区的。
Hash分区:对于给定的key,计算其hashCode,并除以分区个数取余
Range分区:将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
1.自定义分区器
a>HashPartitioner
object PartitionBy {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("Main")
val sc: SparkContext = new SparkContext(sparkConf)
val rdd1: RDD[(String, Int)] = sc.textFile("Day06/input/number").map((_, 1))
//只有k-v值才有分区器
rdd1.saveAsTextFile("./output")
//使用hash分区器
val rdd2: RDD[(String, Int)] = rdd1.partitionBy(new HashPartitioner(3))
rdd2.saveAsTextFile("./output2")
}
}b>RangePartitioner
object PartitionBy {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("Main")
val sc: SparkContext = new SparkContext(sparkConf)
val rdd1= sc.textFile("Day06/input/number").map((_, 1))
//只有k-v值才有分区器
rdd1.saveAsTextFile("./output")
//使用rangePartitioner
val value = new RangePartitioner[String, Int](2, rdd1.sample(false, 0.5))
//range分区器的使用,要定义泛型,传递分区,传递sample
//首先要传递一个分区,传递一个
rdd1.partitionBy(value)
rdd1.saveAsTextFile("./output2")
}
}c>自定义分区
//自定义分区器
case class MyPartitioner(numPartition:Int) extends Partitioner {
override def numPartitions: Int = numPartition
override def getPartition(key: Any): Int = (math.random() * numPartition).toInt
}//自定义分区器的使用
object PartitionBy {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("Main")
val sc: SparkContext = new SparkContext(sparkConf)
val rdd1= sc.textFile("Day06/input/number").map((_, 1))
//只有k-v值才有分区器
rdd1.saveAsTextFile("./output")
//使用rangePartitioner
val value = new RangePartitioner[String, Int](2, rdd1.sample(false, 0.5))
//range分区器的使用,要定义泛型,传递分区,传递sample
//首先要传递一个分区,传递一个
val value1: RDD[(String, Int)] = rdd1.partitionBy(MyPartitioner(2))
value1.saveAsTextFile("./output2")
}
}10.RDD累加器
系统累加器
object MyAccumulator {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setMaster("local[*]").setAppName("myAccumulator"))
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5))
//声明系统累加器
val sum: LongAccumulator = sc.longAccumulator("sum")
rdd.foreach(
num=>{
sum.add(num)
}
)
//获取累加器
println(sum.value)
}
}自定义累加器
1.自定wordcount累加器
//自定义累加器实现wordcount
class DefineAccumulator extends AccumulatorV2[String,mutable.Map[String,Int]]{
val map: mutable.Map[String, Int] = mutable.Map()
//判断累加器是否为初始状态
override def isZero: Boolean = {map.isEmpty}
//复制累加器
override def copy(): AccumulatorV2[String, mutable.Map[String, Int]] = {new DefineAccumulator()}
//重置累加器
override def reset(): Unit = map.clear()
//区内相加
override def add(v: String): Unit = {
//区内相加的定义,如果存在元素,就对key值+1,如果不存在,就添加当前元素,key+1
map(v)=map.getOrElse(v,0)+1
}
//区间相加
override def merge(other: AccumulatorV2[String, mutable.Map[String, Int]]): Unit = {
//区间相加,固定
val map1: mutable.Map[String, Int] = this.value
val map2: mutable.Map[String, Int] = other.value
map2.foreach{
case (k,v) => map1(k)=map1.getOrElse(k,0)+v
}
}
override def value: mutable.Map[String, Int] = map
}2.注册并使用定义累加器
object MyAccumulator2 {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setMaster("local[2]").setAppName("accumulator"))
val word: RDD[String] = sc.textFile("./word.txt")
val words = word.flatMap(_.split(" "))
//new出累加器
val uacc = new DefineAccumulator
//注册累加器
sc.register(uacc)
//使用累加器
words.foreach(uacc.add(_))
println(uacc.value)//注意输出为accumulator的值
}
}11.广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark会为每个任务分别发送。
在整个队列中,仅仅存在一次
object BoardCast {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("emm").setMaster("local[*]"))
val rdd1 = sc.makeRDD(List( ("a",1), ("b", 2), ("c", 3), ("d", 4) ),4)
val list = List(("a",4), ("b", 5), ("c", 6), ("d", 7))
val broadcast: Broadcast[List[(String, Int)]] = sc.broadcast(list)
val value = rdd1.map {
case (key, num) => {
var num1 = 0
for ((k, v) <- broadcast.value) {
if (k == key){
num1=v
}
}
(key, num+num1)
}
}
value.collect().foreach(println)
}
}12.RDD的持久化
12.1为什么要使用RDD的持久化
数据不存储在RDD中
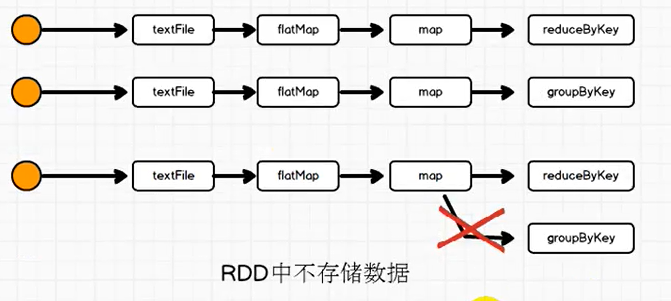
如果一个RDD需要重复使用,需要从头再次执行来获取数据
RDD的对象可以重用,但是数据没法重用
object SparkCore02_RDD_Persist {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("WordCountPersist").setMaster("local[1]")
val sc = new SparkContext(sparkConf)
val list = List("Hello Spark", "Hello Scala")
//生成RDD RDD中不存储数据
val listRDD: RDD[String] = sc.makeRDD(list, 1)
val wordRDD: RDD[String] = listRDD.flatMap(word => word.split(" "))
val tupleRDD: RDD[(String, Int)] = wordRDD.map(word =>
{ println("map阶段")
(word, 1)
})
//分组的操作
val groupRDD: RDD[(String, Iterable[Int])] = tupleRDD.groupByKey()
val resultRDD: RDD[(String, Int)] = tupleRDD.reduceByKey(_ + _)
resultRDD.collect().foreach(println)
println("------------华丽分割线----------------")
groupRDD.collect().foreach(println)
sc.stop()
}
}//结果
map阶段
map阶段
map阶段
map阶段
(Spark,1)
(Hello,2)
(Scala,1)
------------华丽分割线----------------
map阶段
map阶段
map阶段
map阶段
(Spark,CompactBuffer(1))
(Hello,CompactBuffer(1, 1))
(Scala,CompactBuffer(1))发现map阶段运行了两波,所有的执行都会从头开始计算
这样的执行影响了效率
要想解决这个问题,数据持久化提高效率
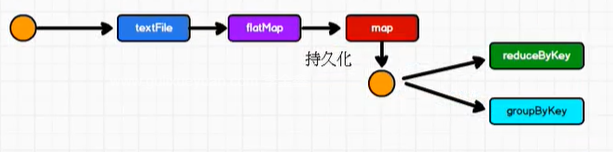
//进行缓存
tupleRDD.cache() //本质是persist
//tupleRDD.cache()
tupleRDD.persist(StorageLevel.MEMORY_AND_DISK)
//memory_only当内存不够的情况下,数据不能溢写到磁盘,会丢失数据
//memory_and_disk当内存不够的情况下,会将数据落到磁盘
//持久化操作,必须在行动算子执行时,完成的
sc.setCheckpointDir("./checkPoint")
//一般要保存到分布式存储中
tupleRDD.checkpoint()
//检查点路径,在作业执行完毕之后也是不会删除的RDD对象的持久化操作不一定为了重用,在数据执行较长,或者数据比较重要的场合也可以进行持久化操作
12.2 三种持久化方法
cache:将数据临时存储在内存中进行数据重用,会添加新的依赖,出现问题从头开始计算
persist:将数据临时存储在磁盘文件中进行数据重用,涉及到磁盘IO,性能较低,但是数据安全,如果作业执行完毕,临时保存在数据文件就会丢失
checkpoint:将磁盘长久地保存在磁盘文件中进行数据重用,涉及到磁盘IO时,性能较低,但是会切断血缘关系,相当于改变数据源
但是数据安全,为了保证数据安全,所以一般情况下,会独立的执行作业,为了能够提高效率,一般情况下,会跟cache联合使用,先cache在使用checkpoint这个时候会保存cache的文件,而不会独立的跑一个单独的任务
graph LR sc-->map-reduceByKey-->cache--保存-->CheckPoint cache-->collect
大区别
cache会添加新的依赖
package com.ecust.rdd.persist
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Jinxin Li
* @create 2020-12-24 14:03
*/
object SparkCore03_RDD_CheckPoint {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("WordCountPersist").setMaster("local[1]")
val sc = new SparkContext(sparkConf)
val list = List("Hello Spark", "Hello Scala")
val listRDD: RDD[String] = sc.makeRDD(list, 1)
val wordRDD: RDD[String] = listRDD.flatMap(word => word.split(" "))
val tupleRDD: RDD[(String, Int)] = wordRDD.map(word => (word, 1))
tupleRDD.cache()
println(tupleRDD.toDebugString)//运行之前看血缘关系
// tupleRDD.persist(StorageLevel.MEMORY_AND_DISK)
// sc.setCheckpointDir("./checkPoint")
// tupleRDD.checkpoint()
val groupRDD: RDD[(String, Iterable[Int])] = tupleRDD.groupByKey()
groupRDD.collect().foreach(println)
println("----------------------------")
println(tupleRDD.toDebugString)//运行之后看血缘
sc.stop()
}
}
(1) MapPartitionsRDD[2] at map at SparkCore03_RDD_CheckPoint.scala:21 [Memory Deserialized 1x Replicated]
| MapPartitionsRDD[1] at flatMap at SparkCore03_RDD_CheckPoint.scala:20 [Memory Deserialized 1x Replicated]
| ParallelCollectionRDD[0] at makeRDD at SparkCore03_RDD_CheckPoint.scala:19 [Memory Deserialized 1x Replicated]
(Spark,CompactBuffer(1))
(Hello,CompactBuffer(1, 1))
(Scala,CompactBuffer(1))
----------------------------
(1) MapPartitionsRDD[2] at map at SparkCore03_RDD_CheckPoint.scala:21 [Memory Deserialized 1x Replicated]
| CachedPartitions: 1; MemorySize: 368.0 B; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B//这里添加了新的依赖
| MapPartitionsRDD[1] at flatMap at SparkCore03_RDD_CheckPoint.scala:20 [Memory Deserialized 1x Replicated]
| ParallelCollectionRDD[0] at makeRDD at SparkCore03_RDD_CheckPoint.scala:19 [Memory Deserialized 1x Replicated]因此cache会在血缘关系中添加新的依赖,一旦出现问题,可以重头读取数据
//使用checkPoint之后
(1) MapPartitionsRDD[2] at map at SparkCore03_RDD_CheckPoint.scala:21 []
| MapPartitionsRDD[1] at flatMap at SparkCore03_RDD_CheckPoint.scala:20 []
| ParallelCollectionRDD[0] at makeRDD at SparkCore03_RDD_CheckPoint.scala:19 []
(Spark,CompactBuffer(1))
(Hello,CompactBuffer(1, 1))
(Scala,CompactBuffer(1))
----------------------------
(1) MapPartitionsRDD[2] at map at SparkCore03_RDD_CheckPoint.scala:21 []
| ReliableCheckpointRDD[4] at collect at SparkCore03_RDD_CheckPoint.scala:31 []使用checkPoint会切断血缘关系,重新建立新的血缘关系等同于改变数据源
12.3源码解析CheckPoint单独执行任务
//SparkContext.scala 2093-2095
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()//-->
//runJob之后调用了doCheckPoint()方法
//-----------------------------
//RDD.scala 1789-1805 doCheckPoint
if (checkpointData.isDefined) {
if (checkpointAllMarkedAncestors) {
dependencies.foreach(_.rdd.doCheckpoint())
}
checkpointData.get.checkpoint()//如果需要checkPoint然后进行checkPoint
} else {
dependencies.foreach(_.rdd.doCheckpoint())
}
//----------------------------------\
//org.apache.spark.rdd.LocalRDDCheckpointData 53-54
if (missingPartitionIndices.nonEmpty) {
rdd.sparkContext.runJob(rdd, action, missingPartitionIndices)
}//单独执行任务12.4使用CheckPoint恢复计算
checkpoint会将结果写到hdfs上,当driver 关闭后数据不会被清除。所以可以在其他driver上重复利用该checkpoint的数据。
checkpoint write data:
sc.setCheckpointDir("data/checkpoint")
val rddt = sc.parallelize(Array((1,2),(3,4),(5,6)),2)
rddt.checkpoint()
rddt.count() //要action才能触发checkpointread from checkpoint data:
package org.apache.spark
import org.apache.spark.rdd.RDD
object RDDUtilsInSpark {
def getCheckpointRDD[T](sc:SparkContext, path:String) = {
//path要到part-000000的父目录
val result : RDD[Any] = sc.checkpointFile(path)
result.asInstanceOf[T]
}
}note:因为sc.checkpointFile(path)是private[spark]的,所以该类要写在自己工程里新建的package org.apache.spark中
example:
val rdd : RDD[(Int, Int)]= RDDUtilsInSpark.getCheckpointRDD(sc, "data/checkpoint/963afe46-eb23-430f-8eae-8a6c5a1e41ba/rdd-0")
println(rdd.count())
rdd.collect().foreach(println)这样就可以原样复原了。
Demo
object SparkCore05_RDD_CheckPointUse {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("WordCountPersist").setMaster("local[1]")
val sc = new SparkContext(sparkConf)
//使用工具类,注意工具类的包,要自己建立,注意泛型
val rdd: RDD[(String, Int)] = RDDUtilsInSpark.getCheckpointRDD[RDD[(String, Int)]](sc, "./checkPoint/1186c961-ddb4-4af5-b7dc-6cc99776490b/rdd-2")
//之前的map之后reduceBykey之前的checkPoint文件
val result: RDD[(String, Int)] = rdd.reduceByKey(_ + _)
result.collect().foreach(println)
sc.stop()
}
}import org.apache.spark.rdd.RDD
//可以恢复checkPoint的工具类,注意放置的包
object RDDUtilsInSpark {
def getCheckpointRDD[T](sc: SparkContext, path: String) = {
//path要到part-000000的父目录
val result: RDD[Any] = sc.checkpointFile(path)
result.asInstanceOf[T]
}
}13.RDD自定义分区器
Spark目前支持Hash分区、Range分区和用户自定义分区。Hash分区为当前的默认分区。分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle后进入哪个分区和Reduce的个数。
1)注意:
(1)只有Key-Value类型的RDD才有分区器,非Key-Value类型的RDD分区的值是None
(2)每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于那个分区的。
package com.ecust.rdd.partition
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext}
/**
* @author Jinxin Li
* @create 2020-12-26 10:52
* 自定义分区规则
*/
object SparkCore01_RDD_Partitioner {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("Partitioner")
val sc = new SparkContext(sparkConf)
val rdd: RDD[(String, String)] = sc.makeRDD(List(
("nba", "xxxxxxxxxxxxxxx"),
("wba", "aaaaaaaaaaaaaa"),
("cba", "dddddddddddd"),
("wcba", "ppppppppppppppppppppppp")
), 3)
/*
自动义分区器,决定数据去哪个分区
*/
val rddPar: RDD[(String, String)] = rdd.partitionBy(new MyPartitioner())
rddPar.saveAsTextFile("./par")
sc.stop()
}
class MyPartitioner extends Partitioner{
//分区数量
override def numPartitions: Int = 3
//返回Int类型,返回数据的分区索引 从零开始
//Key表示数据的KV到底是什么
//根据数据的key值返回数据所在分区索引
override def getPartition(key: Any): Int = {
key match {
case "nba" => 0
case "cba" => 1
case _ => 2
}
/*if (key == "nba"){
0
} else if(key == "cba"){
1
}else{
2
}*/
}
}
}14.RDD的存储与保存
Spark的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:Text文件、Json文件、Csv文件、Sequence文件以及Object文件;
文件系统分为:本地文件系统、HDFS以及数据库。
//集群文件系统存储示例
hdfs://hadoop102:8020/input/1.txt15.RDD的累加器
如果没有累加器,我们计算时只能使用reduce,要想把executor的变量拉回到Driver困难
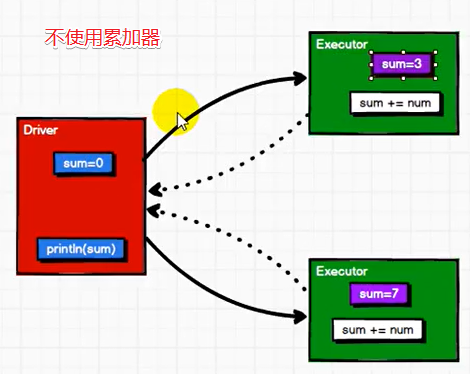
//学前测试
object SparkCore02_RDD_accumulator {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("Partitioner")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),1)
var sum:Int = 0
//行动算子返回非RDD
rdd.foreach(num=>{
sum+=num
println("executor:"+sum)
})
println("driver:"+sum)//打印结果为零,Driver->executor,结果返回不了
sc.stop()
}
}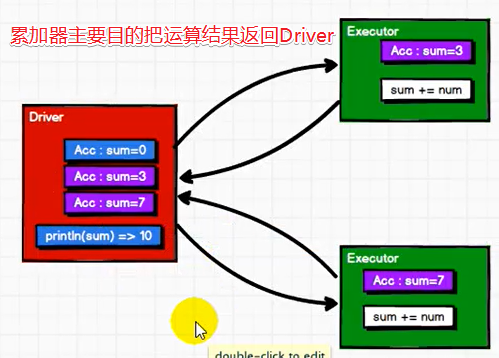
累加器:分布式共享只写变量。(Executor和Executor之间不能读数据)
累加器用来把Executor端变量信息聚合到Driver端。在Driver程序中定义的变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge。
Long累加器Demo
object SparkCore03_RDD_accumulator {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("Partitioner")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),1)
//todo 自定义累加器
val sum: LongAccumulator = sc.longAccumulator("sum")
//系统自带了一些累加器
// sc.doubleAccumulator
// sc.collectionAccumulator()
rdd.foreach(num=>sum.add(num))
println("driver:"+sum.value)
sc.stop()
}
}特殊情况
少加:转换算子中调用累加器,如果没有行动算子的话,name不会执行
多加:转换算子中调用累加器,多次行动算子会调用多次,一般会放在行动算子中进行操作
object SparkCore04_RDD_accumulator {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("Partitioner")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),1)
//todo 自定义累加器
val sum: LongAccumulator = sc.longAccumulator("sum")
//系统自带了一些累加器
// sc.doubleAccumulator
// sc.collectionAccumulator()
val result: RDD[Unit] = rdd.map(num => sum.add(num))
result.collect()
result.collect()//两个行动算子会多加
println("driver:"+sum.value)
sc.stop()
}
}16.RDD的自定义广播变量
分布式共享只写变量
表示累加器的值互相之间是没法访问的,自己能读自己,只有Driver进行读到,然后在Driver端进行合并
我们可以将一些Shuffle的东西使用累加器来实现(==优化==)
比方:需要shuffle的方法就不要shuffle了
闭包数据,都是以Task为单位发送的,每个人物中包含的闭包数据这样可能会导致,一个Executor中含有大量的重复的数据,并且占用大量的内存
Executor本质其实就是JVM,所以在启动时,会自动分配内存
完全可以将任务中的闭包数据放置到Executor的内存中,达到共享的目的
Spark中的广播变量可以将闭包的数据保存在Executor的内存中
分布式共享只读变量
graph TD map-->Executor/task1 map-->Executor/task2 map-->Executor/task3
object SparkCore04_RDD_BroadCast {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("acc")
val sc = new SparkContext(sparkConf)
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val map: mutable.Map[String, Int] = mutable.Map(("a", 4), ("b", 5), ("c", 6))
//定义广播变量
val value: Broadcast[mutable.Map[String, Int]] = sc.broadcast(map)
//每个task都有一份数据
val result: RDD[(String, (Int, Int))] = rdd1.map { case (w, c) => {
val i: Int = value.value.getOrElse(w, 0)
(w, (c, i))
}}
result.collect().foreach(println)
sc.stop()
}
}


