面试题目
1.SQL的谓词下推
原理
不影响逻辑的情况下,尽量将过滤条件提前执行
谓词
sql中的where, spark API 中的 filter
目的
提前过滤部分数据,降低Join等一系列操作的数据量级,尽可能避免因数据倾斜导致程序性能问题
参数:PPD参数
hive.optimize.ppd=false
- Default Value: true
测试
select ename,dept_name
from
E left outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001' and D.dept_id = 'D001');结论
1、对于Join(Inner Join)、Full outer Join,条件写在on后面,还是where后面,性能上面没有区别;
2、对于Left outer Join ,右侧的表写在on后面、左侧的表写在where后面,性能上有提高;
3、对于Right outer Join,左侧的表写在on后面、右侧的表写在where后面,性能上有提高;
2.一个sql join几张表能有几个stage
实战分析
2.1 启动hive on spark
#1.启动hadoop集群
myhadoop.sh start
=============== hadoop102 ===============
48578 NameNode
49300 JobHistoryServer
48727 DataNode
49114 NodeManager
=============== hadoop103 ===============
25600 DataNode
25819 ResourceManager
25964 NodeManager
=============== hadoop104 ===============
23125 DataNode
23382 NodeManager
23224 SecondaryNameNode
#2.启动元数据库
hive --service metastore
=============== hadoop102 ===============
48578 NameNode
49300 JobHistoryServer
51399 RunJar #多了一个RunJar
48727 DataNode
49114 NodeManager
=============== hadoop103 ===============
25600 DataNode
25819 ResourceManager
25964 NodeManager
=============== hadoop104 ===============
23125 DataNode
23382 NodeManager
23224 SecondaryNameNode
#3.启动hiveServer2
hive --service hiveserver2
=============== hadoop102 ===============
48578 NameNode
53570 RunJar #hiveserver2
49300 JobHistoryServer
51399 RunJar #metadata
48727 DataNode
49114 NodeManager
=============== hadoop103 ===============
25600 DataNode
25819 ResourceManager
25964 NodeManager
=============== hadoop104 ===============
23125 DataNode
23382 NodeManager
23224 SecondaryNameNode
#4.使用beeline客户端
bin/beeline -u jdbc:hive2://hadoop102:10000 -n atguigu
=============== hadoop102 ===============
48578 NameNode
53570 RunJar
49300 JobHistoryServer
51399 RunJar
48727 DataNode
56506 RunJar
49114 NodeManager
=============== hadoop103 ===============
25600 DataNode
25819 ResourceManager
25964 NodeManager
=============== hadoop104 ===============
23125 DataNode
23382 NodeManager
23224 SecondaryNameNode #没有变化
#5.退出beeline 使用DG连接总结
启动两个runJar服务
beeline客户端属于JDBC连接,但是没有进程
2.2加入测试用两个表并简单查询
dept
-- dept
+--------------+-------------+-----------+
| dept.depart | dept.id | dept.loc |
+--------------+-------------+-----------+
| 10 | ACCOUNTING | 1700 |
| 20 | RESEARCH | 1800 |
| 30 | SALES | 1900 |
| 40 | OPERATIONS | 1700 |
+--------------+-------------+-----------+emp
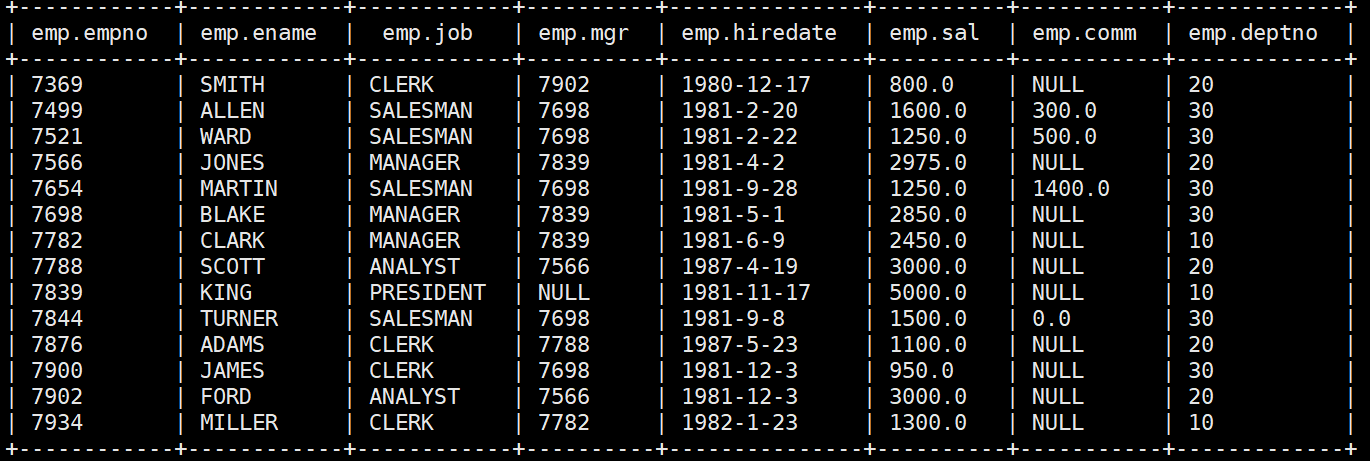
需求1:查询表
select
empno,
ename,
job,mgr,
hiredate,
sal,
comm,
deptno
from emp;此时已经连接
jpsall
=============== hadoop102 ===============
48578 NameNode
53570 RunJar
49300 JobHistoryServer
51399 RunJar
48727 DataNode
49114 NodeManager
=============== hadoop103 ===============
25600 DataNode
25819 ResourceManager
25964 NodeManager
=============== hadoop104 ===============
23125 DataNode
23382 NodeManager
23224 SecondaryNameNode总结
简单查询类似于
select name from user;不走spark任务,是hive与元数据跟 HDFS 交互
2.3 双表join测试
需求
根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称;
-- 文字分析 需求快速上手
select 员工编号,员工名称,部门名称
from 员工表
join 部门表
on 员工表.部门编号=部门表.部门编号
-- 具体sql
select
e.empno,
e.ename,
d.depart,
d.id
from
emp e
join
dept d
on e.deptno = d.depart;分析
程序总计跑了41秒
显然第一次跑任务时间长是由于spark在创建一个任务,但是具体详情,我去分析一下
# jpsall
=============== hadoop102 ===============
48578 NameNode
53570 RunJar
49300 JobHistoryServer
51399 RunJar
48727 DataNode
80441 YarnCoarseGrainedExecutorBackend #第一次任务多出 Executor进程
49114 NodeManager
=============== hadoop103 ===============
25600 DataNode
25819 ResourceManager
25964 NodeManager
=============== hadoop104 ===============
23125 DataNode
23382 NodeManager
23224 SecondaryNameNode
27324 ApplicationMaster #第一次任务多出 Driver进程
27711 YarnCoarseGrainedExecutorBackend #第一次任务多出 Executor进程可以看出第一跑任务之后,spark在yarn资源上生成了三个进程
27324 ApplicationMaster #Driver
80441 YarnCoarseGrainedExecutorBackend #Executor计算对象
27711 YarnCoarseGrainedExecutorBackend #Executor备注:关于Executor到底是对象还是进程,官网说进程,源码说对象,jps说进程不是这个,这个比较晕
yarn
(1)任务号

Running Containers 3 (2个Executor,1个Driver),2个Executor,内存等都是spark的默认配置
(2)时间线
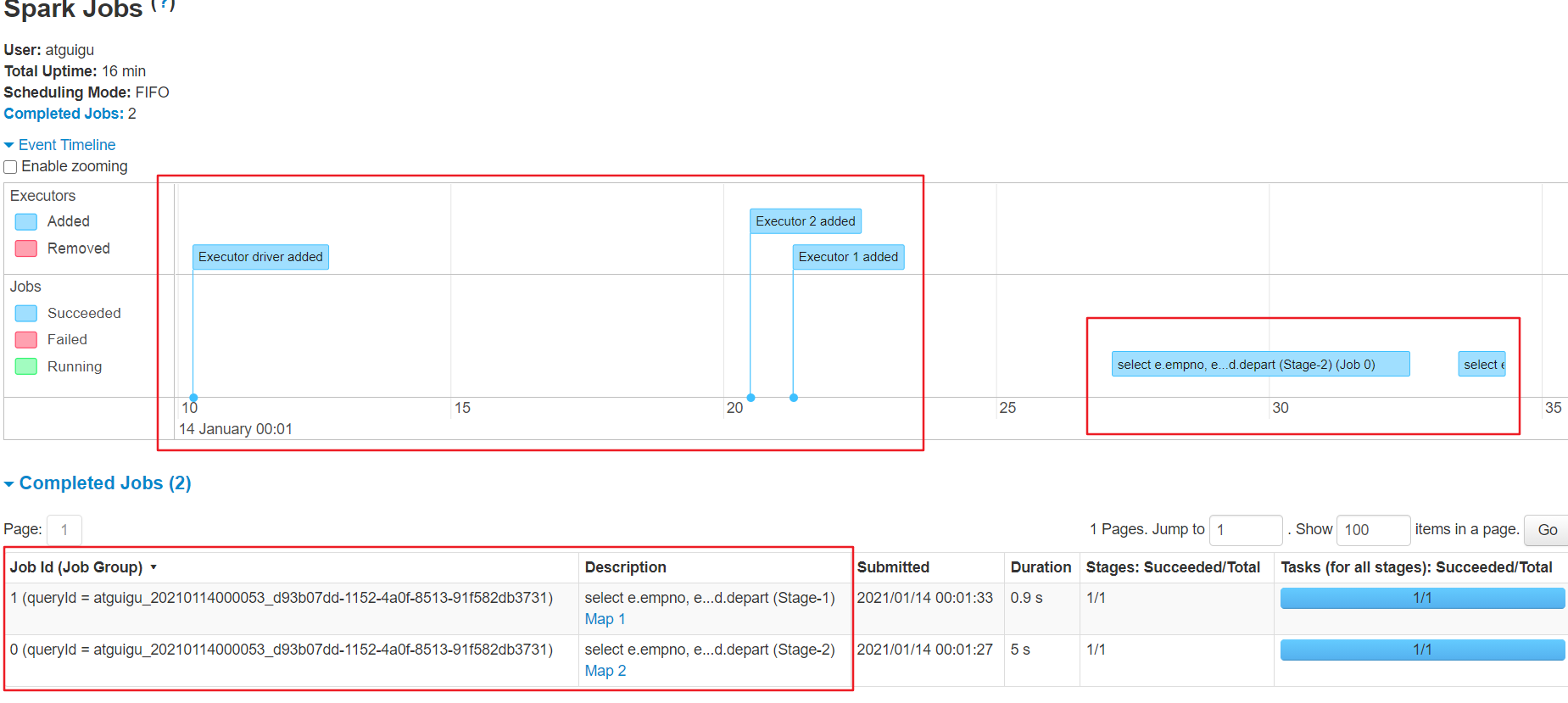
可以看见Driver与Executor创建时间
同时发现,一个简单的两个表的join竟然运行了两个job,也就是代表了使用了两个行动算子
//知识点归纳1 划分
Application:初始化一个SparkContext即生成一个Application
Job:一个Action算子就会生成一个Job
Stage:Stage等于宽依赖(ShuffleDependency)+1
Task:一个Stage阶段中,最后一个RDD分区个数就是Task的个数;
//知识点归纳2 行动算子
reduce()
collect()
count()
first()
take()
takeOrdered()
aggregate()
fold()
countByKey()
save()
foreach()DAG
第一个任务执行的DAG
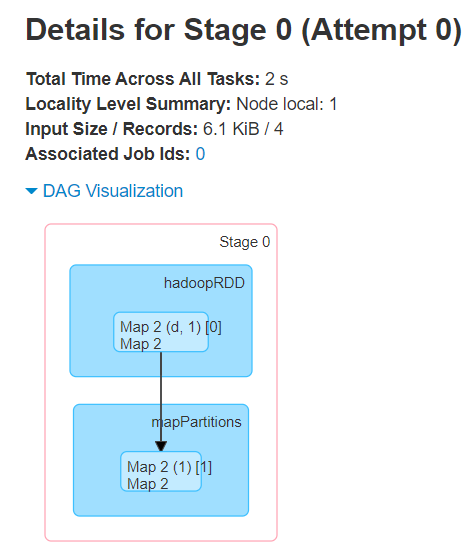
第二个任务执行的DAG
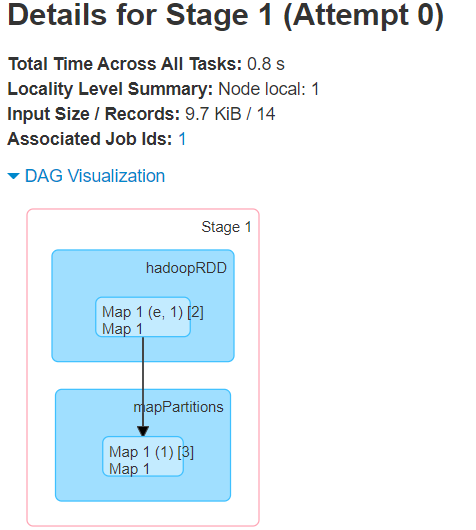
总结
一个简单的join
两个job
每个job一个stage
跑的都是map
2.4 三表join测试
select
e.empno,
e.ename,
d.depart,
d.id,
l.loc
from
emp e
join
dept d
on e.deptno = d.depart
join location l
on d.loc = l.loc;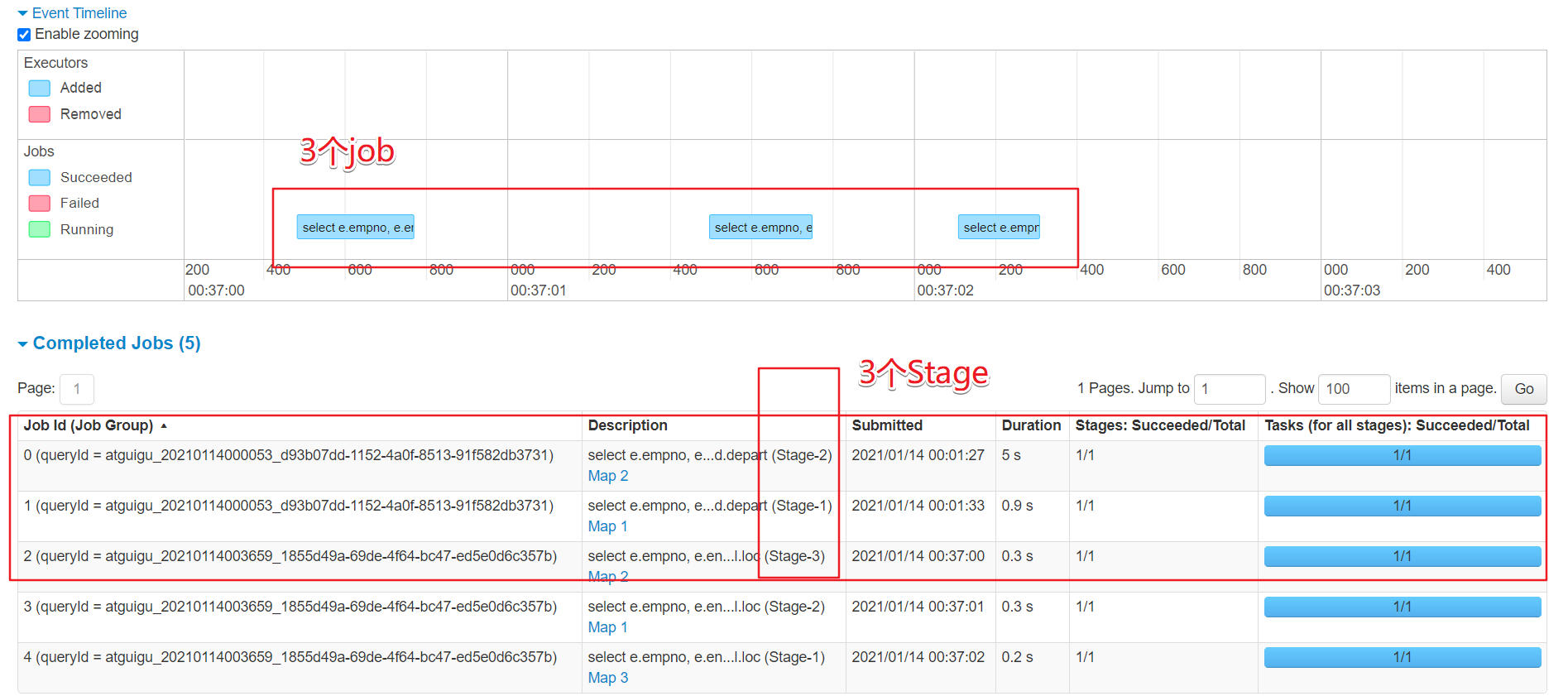
2.5 总结
没有什么难度
关键是架构问题,李晓磊老师根本不带我们分析内部优化与DAG执行计划,导致我们就懂几个业务SQL
总而言之就是
join=shuffle
一个join就有两个阶段
三表join有两个join有三个阶段,这很好理解
但是在这里与spark本身不同的是,这个一个stage直接划分为一个job(推测可能与mr的划分机制有关)
2.6附加1
DAG图之看到map阶段(mapPartitions算子)
那reduce阶段怎么来的
执行sql+where
select
e.empno,
e.ename,
d.depart,
d.id,
l.loc
from
emp e
join
dept d
on e.deptno = d.depart
join location l
on d.loc = l.loc
where d.loc=1800;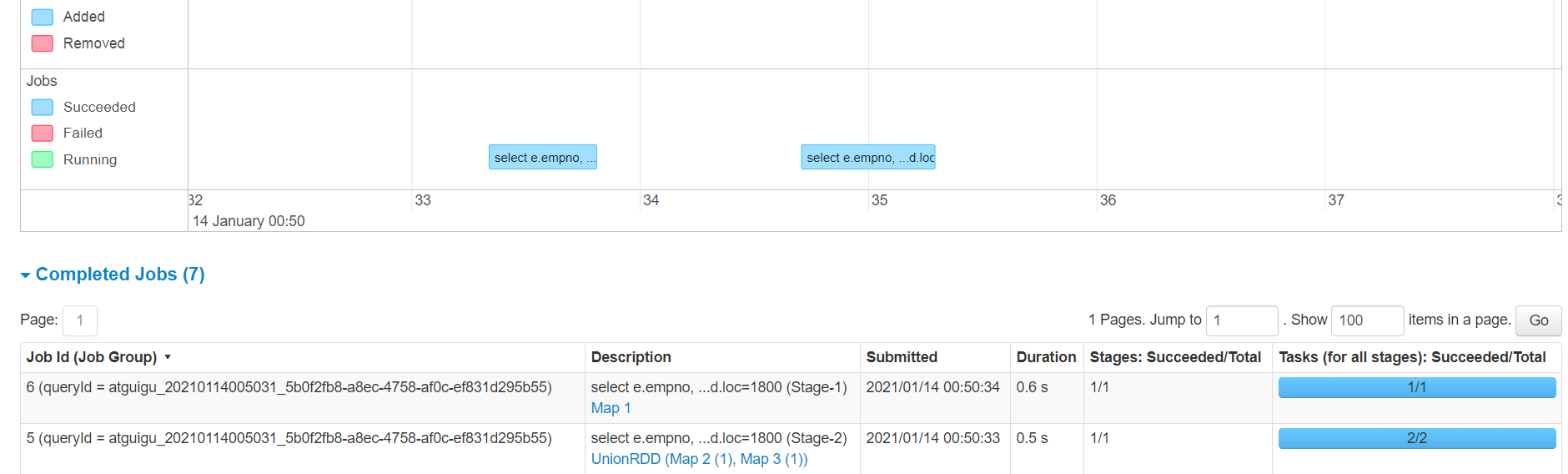
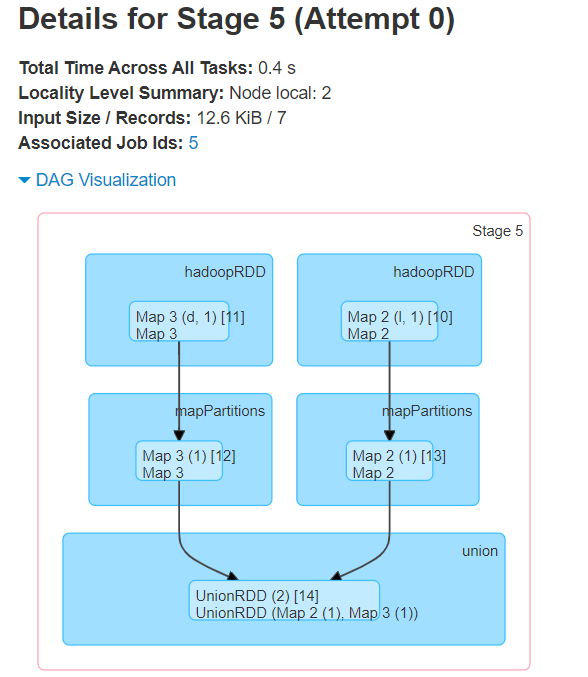
结论
放上where变成了两个job,两个stage..其中有个DAG不一样
2.7附加2
运行一下真正的数仓sql看看吧
需求:7连3
select
'2020-06-16',
concat(date_add('2020-06-16',-6),'_','2020-06-16'),
count(*)
from
(
select mid_id
from
(
select mid_id
from
(
select
mid_id,
date_sub(dt,rank) date_dif
from
(
select
mid_id,
dt,
rank() over(partition by mid_id order by dt) rank
from dws_uv_detail_daycount
where dt>=date_add('2020-06-25',-6) and dt<='2020-06-25'
)t1
)t2
group by mid_id,date_dif
having count(*)>=3
)t3
group by mid_id --去重,防止一个设备有两段连续超过3天的日子
)t4;
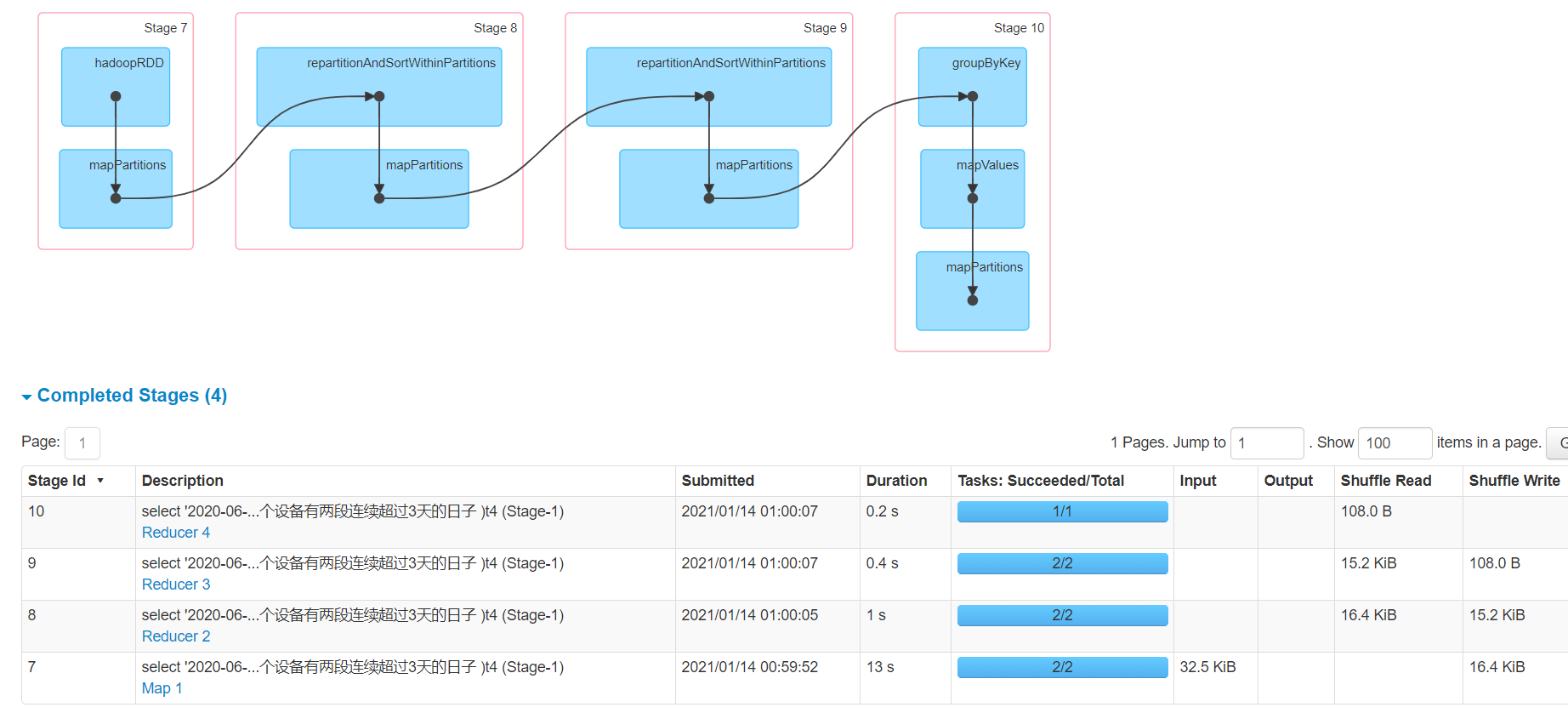
震惊了
七连三只跑了一个job
四个stage
好久不看数仓,这个复杂程度日后在分析吧,或者你们谁有时间可以琢磨一下
晓磊老师没讲这些东西确实可气
网上的东西都不靠谱
源文件
show databases;
create database test;
create table if not exists dept(
depart int,
id string,
loc int)
row format delimited fields terminated by '\t';
create table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/dept' into table dept;
load data local inpath '/opt/module/data/emp' into table emp;
select * from emp;
select * from dept;
select
empno,
ename,
job,
mgr,
hiredate,
sal,
comm,
deptno
from emp;
select
e.empno,
e.ename,
d.depart,
d.id,
l.loc
from
emp e
join
dept d
on e.deptno = d.depart
join location l
on d.loc = l.loc
where d.loc=1800;
create table if not exists location(
loc int,
loc_name string
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/location' into table location;
select * from location;
location:
1700 Beijing
1800 London
1900 Tokyo
dept:
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
emp:
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
select
'2020-06-16',
concat(date_add('2020-06-16',-6),'_','2020-06-16'),
count(*)
from
(
select mid_id
from
(
select mid_id
from
(
select
mid_id,
date_sub(dt,rank) date_dif
from
(
select
mid_id,
dt,
rank() over(partition by mid_id order by dt) rank
from dws_uv_detail_daycount
where dt>=date_add('2020-06-25',-6) and dt<='2020-06-25'
)t1
)t2
group by mid_id,date_dif
having count(*)>=3
)t3
group by mid_id --去重,防止一个设备有两段连续超过3天的日子
)t4;



