ElasticSearch_总结
1.lucene
lucene,就是一个jar包,里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法。我们就用java开发的时候,引入lucene jar,然后基于lucene的api进行去进行开发就可以了。
2.倒排索引
可以看到 Lucene 为倒排索引(Term Dictionary)部分又增加一层Term Index结构,用于快速定位,而这Term Index是缓存在内存中的,但MySQL的B+tree不在内存中,所以整体来看ES速度更快,但同时也更消耗资源(内存、磁盘)。
3.B+tree
是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。(排序查找算法系统的学习,可以在Java知音公众号回复“排序算法聚合”)
MySQL使用的B+tree 是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。(排序查找算法系统的学习,可以在Java知音公众号回复“排序算法聚合”)
3.Elasticsearch核心概念
3.1近实时
近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级。
3.2Cluster(集群)
集群包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
#cluster.name
#-----------------------------------------------
#1 如果要配置集群需要两个节点上的elasticsearch配置的cluster.name相同,都启动可以自动组成集群,这里如果不改cluster.name则默认是cluster.name=my-application
#2 nodename随意取但是集群内的各节点不能相同
#3 修改后的每行前面不能有空格,修改后的“:”后面必须有一个空格3.3Node(节点)
集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群。
3.4Index(索引-数据库)
索引包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
3.5Type(类型-表)
6.0版本之前每个索引里都可以有多个type;
6.0版本之后每个索引里面只能有一个Type,一般使用_doc代替了。
商品index,里面存放了所有的商品数据,商品document
商品type:product_id,product_name,product_desc,category_id,category_name,service_period
每一个type里面,都会包含一堆document
{
"product_id": "1",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}3.6Document(文档-行)
文档是ES中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。
3.7Field(字段-列)
一个document里面有多个field,每个field就是一个数据字段。
#product document
{
"product_id": "1",
"product_name": "高露洁牙膏",
"product_desc": "高效美白",
"category_id": "2",
"category_name": "日化用品"
}3.8Mapping(映射-约束)
数据如何存放到索引对象上,需要有一个映射配置,包括:数据类型、是否存储、是否分词等。
Mapping用来定义Document中每个字段的类型,即所使用的分词器、是否索引等属性,非常关键等。
3.9ElasticSearch与数据库的类比
| 关系型数据库(比如Mysql) | 非关系型数据库(Elasticsearch) |
|---|---|
| 数据库Database | 索引Index |
| 表Table | 类型Type(6.0版本之后在一个索引下面只能有一个,7.0版本之后取消了Type) |
| 数据行Row | 文档Document(JSON格式) |
| 数据列Column | 字段Field |
| 约束 Schema | 映射Mapping |
3.10ElasticSearch存入数据和搜索数据机制
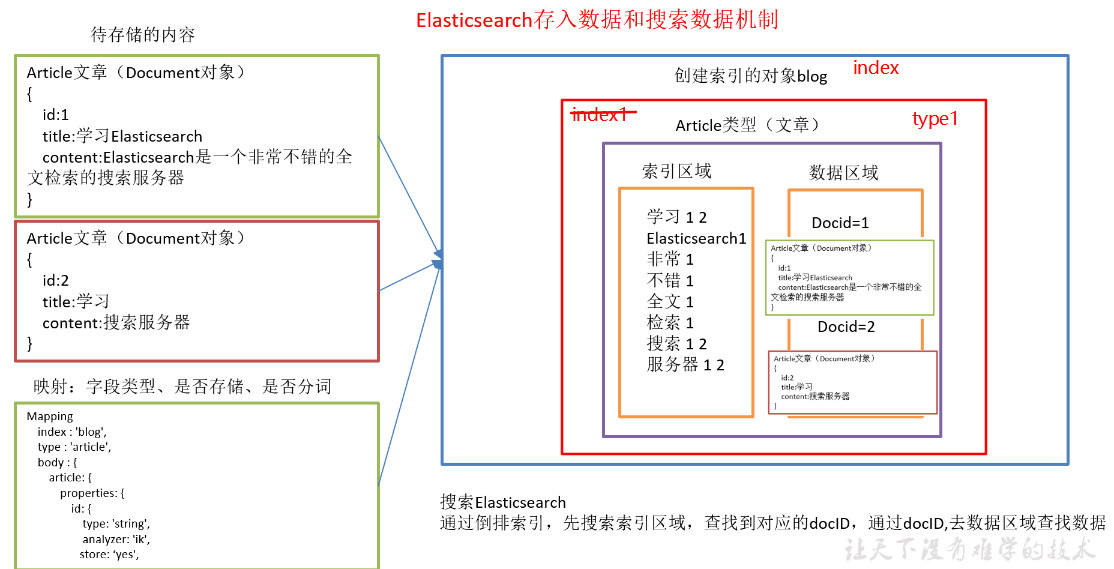
1)索引对象(blog=index):存储数据的表结构,任何搜索数据,存放在索引对象上 。
2)映射(mapping):数据如何存放到索引对象上,需要有一个映射配置, 包括:数据类型、是否存储、是否分词等。
3)文档(document):一条数据记录,存在索引对象上。
4)文档类型:一个索引对象,存放多种类型数据,数据用文档类型进行标识。
4.总结
总而言之 搜索是把所有数据进行json格式化,格式化的方法使用Mapping映射约束成json文件,然后赋予Docid,然后通过倒排索引的方法将字段提取出来,提供 索引(Docid结构)
5.代码
#查看元数据信息
GET _cat/nodes
GET _cat/health
GET _cat/indices
GET _cat/master
#手动创建Mapping
PUT student
{
"mappings": {
"_doc":{
"properties":{
"stu_id":{
"type":"keyword"
},
"name":{
"type":"text"
},
"gender":{
"type":"boolean"
},
"birth":{
"type":"date"
}
}
}
}
}
#查看Mapping信息
GET student/_mapping
#使用PUT方式向student索引中插入数据:幂等操作
PUT student/_doc/1001
{
"stu_id":"1111",
"name":"张三",
"gender":false,
"birth":"2020-12-05"
}
#插入错误类型的数据
PUT student/_doc/1002
{
"stu_id":"2222",
"name":"李四",
"gender":"aaaa",
"birth":"2020-12-05"
}
#使用POST方式向student索引中插入数据
POST student/_doc
{
"stu_id":"2222",
"name":"李四",
"gender":true,
"birth":"2020-12-05"
}
#查询索引数据
GET student/_search
#自动创建Mapping(直接向一个不存在的Index中插入数据即可)
PUT student1/_doc/1001
{
"stu_id":1111,
"name":"张三",
"gender":false,
"birth":"2020-12-05"
}
#查询自动创建Mapping的映射信息
GET student1/_mapping
#查看keyWord类型分词结果(报错,不分词)
GET _analyze
{
"keyword":"我是程序员"
}
#查看Text类型分词结果(将汉字独立拆开)
GET _analyze
{
"text":"我是程序员"
}
#查看使用IK分词器之后的分词效果
GET _analyze
{
"analyzer": "ik_smart",
"text":"我是程序员"
}
GET _analyze
{
"analyzer": "ik_max_word",
"text":"我是程序员"
}
#创建Index
PUT stu1
{
"mappings": {
"_doc":{
"properties":{
"stu_id":{
"type":"keyword"
},
"name":{
"type":"keyword"
},
"class_id":{
"type":"integer"
},
"gender":{
"type":"text"
},
"age":{
"type":"integer"
},
"favo1":{
"type":"keyword"
},
"favo2":{
"type":"text",
"analyzer": "ik_max_word"
}
}
}
}
}
#插入测试数据
PUT stu1/_doc/1001
{
"stu_id":"1111",
"name":"国亮",
"class_id":"0720",
"gender":"male",
"age":18,
"favo1":"唱歌跳舞,乒乓球",
"favo2":"唱歌跳舞,乒乓球"
}
PUT stu1/_doc/1002
{
"stu_id":"2222",
"name":"王斌",
"class_id":"0720",
"gender":"male",
"age":3,
"favo1":"睡觉,做梦,梦游",
"favo2":"睡觉,做梦,梦游"
}
PUT stu1/_doc/1003
{
"stu_id":"3333",
"name":"班长",
"class_id":"0720",
"gender":"female",
"age":17,
"favo1":"抽烟,喝酒,烫头,羽毛球",
"favo2":"抽烟,喝酒,烫头,羽毛球"
}
PUT stu1/_doc/1004
{
"stu_id":"4444",
"name":"文康",
"class_id":"0720",
"gender":"male",
"age":60,
"favo1":"太极,广场舞,闪电舞",
"favo2":"太极,广场舞,闪电舞"
}
PUT stu1/_doc/1005
{
"stu_id":"5555",
"name":"加明",
"class_id":"0720",
"gender":"male",
"age":22,
"favo1":"蹦迪,大保健,洗脚",
"favo2":"蹦迪,大保健,洗脚"
}
PUT stu1/_doc/1006
{
"stu_id":"6666",
"name":"张小芳",
"class_id":"0720",
"gender":"female",
"age":24,
"favo1":"来,手机交一下,胸卡口罩戴起来",
"favo2":"来,手机交一下,胸卡口罩戴起来"
}
PUT stu1/_doc/1007
{
"stu_id":"7777",
"name":"马丁",
"class_id":"0523",
"gender":"male",
"age":70,
"favo1":"_省略,scala,编程,橄榄球",
"favo2":"_省略,scala,编程,橄榄球"
}
PUT stu1/_doc/1008
{
"stu_id":"8888",
"name":"安小妮",
"class_id":"0523",
"gender":"female",
"age":30,
"favo1":"来,手机交一下,胸卡口罩戴起来",
"favo2":"来,手机交一下,胸卡口罩戴起来"
}
#查询数据
GET stu1/_search
#全值匹配查询filter(where):指的是将查询条件当做一个整体
GET stu1/_search
{
"query": {
"bool": {
"filter": {
"term": {
"favo1": "来,手机交一下,胸卡口罩戴起来"
}
}
}
}
}
GET stu1/_search
{
"query": {
"bool": {
"filter": {
"term": {
"favo2": "来,手机交一下,胸卡口罩戴起来"
}
}
}
}
}
#分词匹配match:将查询条件做分词,但是使用的分词规则与原字段相同
GET stu1/_search
{
"query": {
"match": {
"favo1": "来,手机交一下,胸卡口罩戴起来"
}
}
}
GET stu1/_search
{
"query": {
"match": {
"favo2": "来,手机交一下,胸卡口罩戴起来"
}
}
}
GET stu1/_search
{
"query": {
"match": {
"favo1": "球"
}
}
}
GET stu1/_search
{
"query": {
"match": {
"favo2": "球"
}
}
}
#结合全值匹配以及分词匹配查询
#需求,查询出0720班级爱好包含"球"
GET stu1/_search
{
"query": {
"bool": {
"filter": {
"term": {
"class_id": "0720"
}
},
"must": [
{
"match": {
"favo2": "球"
}
}
]
}
}
}
#模糊查询
GET stu1/_search
{
"query": {
"fuzzy": {
"gender": "female"
}
}
}
#聚合查询:单个聚合条件
GET stu1/_search
{
"aggs": {
"countByClass": {
"terms": {
"field": "class_id",
"size": 10
}
}
}
}
GET stu1/_search
{
"aggs": {
"maxAge": {
"max": {
"field": "age"
}
}
}
}
#聚合查询:多个聚合条件:没有关联
GET stu1/_search
{
"aggs": {
"countByClass": {
"terms": {
"field": "class_id",
"size": 10
}
},
"maxAge": {
"max": {
"field": "age"
}
}
}
}
#聚合查询:多个聚合条件:嵌套关联
GET stu1/_search
{
"aggs": {
"countByClass": {
"terms": {
"field": "class_id",
"size": 10
},
"aggs": {
"maxAge": {
"max": {
"field": "age"
}
}
}
}
}
}
#分页查询 from=(页码-1)*size
GET stu1/_search
{
"from": 2,
"size": 2
}
#综合需求:查询0720班级爱好包含"球"的人,并计算其中最大年纪是多少,同时使用分页查询
GET stu1/_search
{
"query": {
"bool": {
"filter": {
"term": {
"class_id": "0720"
}
},
"must": [
{
"match": {
"favo2": "球"
}
}
]
}
},
"aggs": {
"maxAge": {
"max": {
"field": "age"
}
}
},
"from": 1,
"size": 1
}


