0x0.Standalone模式
快速上手
#解压缩
tar -zxvf flink-1.10.1-bin-scala_2.12.tgz -C /opt/module
#修改flink/conf/flink-conf.yaml配置文件
jobmanager.rpc.address: hadoop102 #修改jobmanager
#修改/conf/slaves文件
hadoop102
hadoop103
hadoop104
...#添加集群机器
#分发
xsync flink/
#启动
bin/start-cluster.sh
#监控
http://hadoop102:8081 #提交任务
#提交
bin/flink run -c com.atguigu.wc.Flink03_WordCount_Unbounded -p 2 FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host hadoop102 --port 7777
#-c 全类名
#-p 并行度
#jar包
#--host 参数
#--prot 参数Socket端口是不可以并行的
example
/**
* @author Jinxin Li
* @create 2021-01-06 20:12
*/
public class Flink01_Wc_ParameterToolExample {
public static void main(String[] args) throws Exception {
//0x0 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(3);
//0x1 从端口中获取数据
//DataStreamSource<String> portDS = env.socketTextStream("hadoop102", 9999);
//工具类需要传入参数 --host hadoop102 --port 9999
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
DataStreamSource<String> portDS = env.socketTextStream(host, port);
//0x2 处理数据
SingleOutputStreamOperator<Tuple2<String, Integer>> word2One = portDS.flatMap(new Function01_MyFlatMapFunction());
SingleOutputStreamOperator<Tuple2<String, Integer>> result = word2One.keyBy(0).sum(1);
//0x3 打印数据
result.print();
//0x4 启动
env.execute();
}
}

0x1.Yarn-Session模式
Start a long-running Flink cluster on YARN
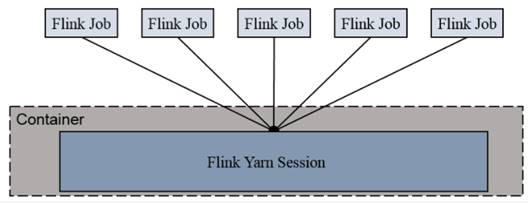
Session-Cluster模式需要先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。
如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。
所有作业共享Dispatcher和ResourceManager;共享资源;适合规模小执行时间短的作业。
在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交。这个flink集群会常驻在yarn集群中,除非手工停止。
局限性
我们在配置slot的时候,就限定了session的slot的个数,将slot的个数固定,无法根据内存灵活启动.
比如我们三台机器,每台机器配置2个slot,一个任务最大并行度为3,则只能启动两个任务.即使集群还有剩余内存
快速上手
Start a YARN session where the job manager gets 1 GB of heap space and the task managers 4 GB of heap space assigned:
# get the hadoop2 package from the Flink download page at
# https://flink.apache.org/downloads.html
tar xvzf flink-1.10.2-bin-hadoop2.tgz
#需要添加额外的hadoop支持 编译
cd flink-1.10.2/
./bin/yarn-session.sh -jm 1024m -tm 4096mSpecify the -s flag for the number of processing slots per Task Manager.
We recommend to set the number of slots to the number of processors per machine.
Once the session has been started, you can submit jobs to the cluster using the ./bin/flink tool.
-n\工本费(--container):TaskManager的数量。这参数已经过时无效
-s(--slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
-jm:JobManager的内存(单位MB)。
-tm:每个taskmanager的内存(单位MB)。
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行。这个参数也已经过时无效启动
#启动hadoop集群
myhadoop.sh start
#启动服务
bin/yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d#提交任务
./flink run -c com.ecust.parametertool.Flink01_Wc_ParameterToolExampleFlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host hadoop102 --port 99990x2.Yarn-Per-Job模式
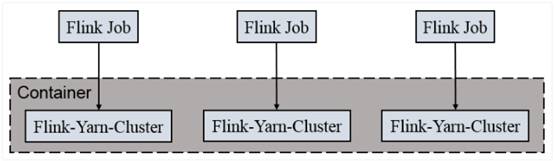
一个Job会对应一个集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。
独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。
任务执行完成之后创建的集群也会消失。
1.快速上手
#启动hadoop集群
myhadoop.sh start
#不启动yarn-session,直接执行job
bin/flink run \
-m yarn-cluster \
-c com.ecust.parametertool.Flink01_Wc_ParameterToolExample \
flink-utils-1.0-SNAPSHOT.jar \
--host hadoop102 \
--port 99992.配置多队列
vim /opt/module/hadoop-3.1.3/etc/hadoop/capacity-scheduler.xml<configuration>
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<value>50</value>
<description>
hive队列的容量为50%
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factor</name>
<value>1</value>
<description>
一个用户最多能够获取该队列资源容量的比例,取值0-1
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacity</name>
<value>80</value>
<description>
hive队列的最大容量(自己队列资源不够,可以使用其他队列资源上限)
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.state</name>
<value>RUNNING</value>
<description>
开启hive队列运行,不设置队列不能使用
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name>
<value>*</value>
<description>
访问控制,控制谁可以将任务提交到该队列,*表示任何人
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name>
<value>*</value>
<description>
访问控制,控制谁可以管理(包括提交和取消)该队列的任务,*表示任何人
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name>
<value>*</value>
<description>
指定哪个用户可以提交配置任务优先级
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name>
<value>-1</value>
<description>
hive队列中任务的最大生命时长,以秒为单位。任何小于或等于零的值将被视为禁用。
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name>
<value>-1</value>
<description>
hive队列中任务的默认生命时长,以秒为单位。任何小于或等于零的值将被视为禁用。
</description>
</property>
</configuration>3.执行命令
#查看命令
bin/flink
#指定队列 --yarnqueue
-yqu hive对于per-job模式而言,能够充分使用集群资源
4.Container与Slot
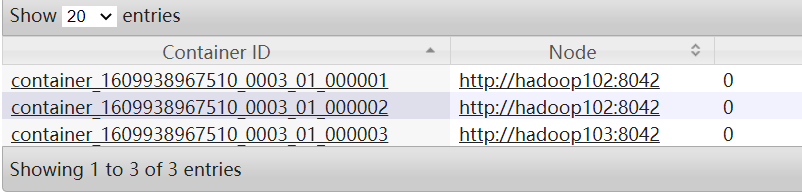
三个并行度的任务启动了三个container
一个用来封装Driver
每个container里面有一个TaskManager,里面封装了2个slot
5.运行内存核算
实现跳转功能需要按住Ctrl键
计算示例使用上面example
虚拟机运行总内存
#hadoop102
8g
#hadoop103
4g
#hadoop104
4gflink的Per-Job内存
jobmanager.heap.size: 1024m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 2
parallelism.default: 1估计内存
目前总队列2条,hive与default,各占用50%运行内存
每个任务使用1024M的jobManager
1728M的taskManager2个
总计
$$
1728M(TaskManager)*2+1024M(JobManager)=4480M=4.375G
$$
并行度为3,使用3个slot
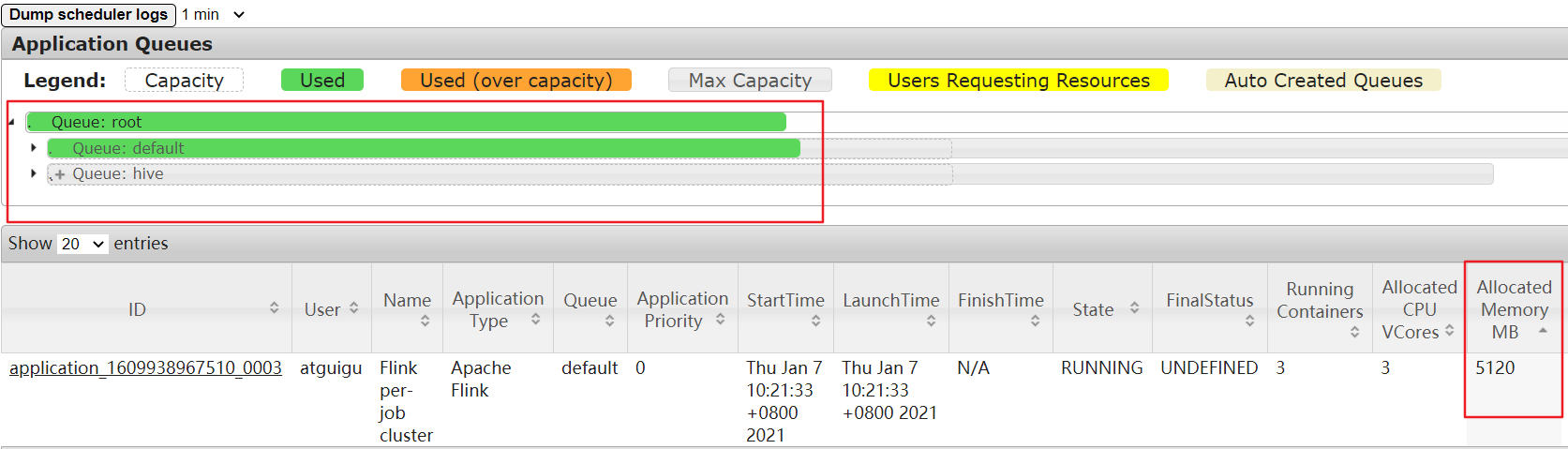
可以发现单个job提交后运行内存为5G
我们继续在default提交任务
bin/flink run \
-m yarn-cluster \
-c com.ecust.parametertool.Flink01_Wc_ParameterToolExample \
-nm test01 \
flink-utils-1.0-SNAPSHOT.jar \
--host hadoop102 \
--port 9999总内存还剩余
$$
12G(AllMemory)-5G(singlejob)=7G(RemainMemory)
$$
单队列还剩余
$$
6G(DefaultMemory)-5G(singlejob)=1G(RemainMemory)
$$
所以此任务已经无法启动
提交任务到另一个队列
bin/flink run \
-m yarn-cluster \
-c com.ecust.parametertool.Flink01_Wc_ParameterToolExample \
-nm test02 \
-yqu hive \
flink-utils-1.0-SNAPSHOT.jar \
--host hadoop102 \
--port 9999此时任务能够成功运行
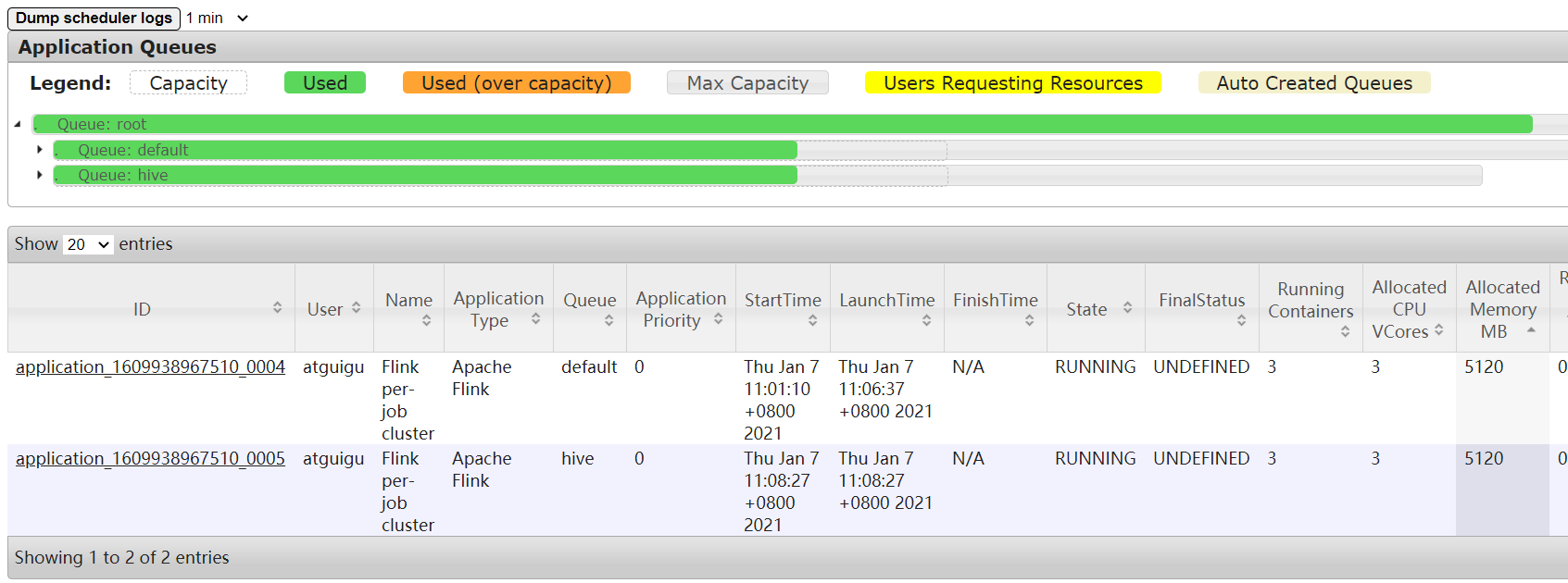
这个时候任务已经提交到集群,即使关闭提交客户端窗口,任务依旧执行
6.队列的思考
首先把之前的example的jar的运行并行度设置为1
常规思想说的是,一般来讲,在一个FIFO调度器中,提交一个任务后,不会在启动其他任务,如果提交其他任务,会处理卡死状态
example
#在hadoop102提交一个任务
bin/flink run \
-m yarn-cluster \
-c com.ecust.parametertool.Flink01_Wc_ParameterToolExample \
-nm test01 \
flink-utils-1.0-SNAPSHOT.jar \
--host hadoop102 \
--port 9999
#在hadoop102再次提交一个任务
bin/flink run \
-m yarn-cluster \
-c com.ecust.parametertool.Flink01_Wc_ParameterToolExample \
-nm test01 \
flink-utils-1.0-SNAPSHOT.jar \
--host hadoop102 \
--port 9999
#就会发现两个任务,在同一个队列无法运行,就算把堆内存,跟slot更改,也无法运行问题
这个时候会单纯的认为是因为程序在调度时卡住,当调度没有完成时,无法进行下一个任务的提交
一个队列是根本无法运行两个任务的,FIFO队列是先进先出
解析
#打开容量调度器配置文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/capacity-scheduler.xml查看下面参数
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>#这个参数 maximum-am-resource-percent
代表的是application masters占集群的总资源占比是0.1
我们的集群是8/4/4一共是16g的运行内存,我们仅仅有1.6g内存去启动application master
而我们的flink-conf.yaml配置的jobManager是1024g
我们的application master = jobManager + 内置resourceManager
在1.6g的内存下无法存在两个jobManager
#若想运行两个job
修改成0.15先 16*0.15=2.4G,运行两个application master足够了
试一试吧
结果不行
因为双队列 6*0.15=1.2G
#需要重启yarn
继续修改成0.5 6*0.5 = 3g<!-- /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml -->
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property><!-- /opt/module/hadoop-3.1.3/etc/hadoop/capacity-scheduler.xml -->
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.5</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>下面是我的Flink-Conf.yaml的修改配置,JobManager1G,TaskManager占用1G内存
jobmanager.rpc.address: hadoop102
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The heap size for the JobManager JVM
# jobmanager.heap.size: 1024m
jobmanager.heap.size: 1024m
# The total process memory size for the TaskManager.
#
# Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.
# taskmanager.memory.process.size: 1728m
taskmanager.memory.process.size: 1024m
进一步观察程序占用内存
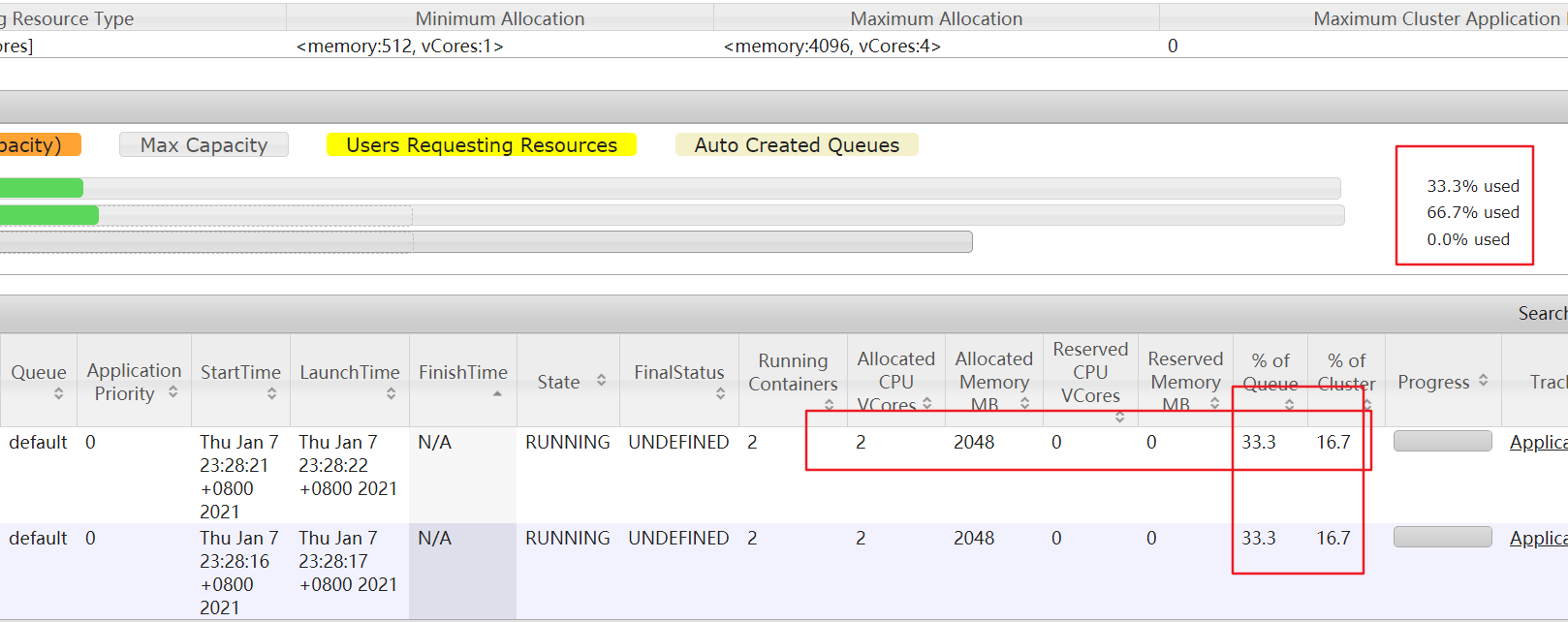
整体内存12g
则JobManager1g,TaskManager(就执行一个,1g)
FIFO是先进先出调度器.



