1. 事务型事实表-订单明细事实表
1.1 什么是订单明细事实表?
订单明细,指的就是订单里的某一种商品的相关信息,把粒度降低到每类商品(SKU)上
事务型:就是只能增,不能删改
事实表:存在度量值
1.1.1 逆向思维理解
抛开其他,假如要创建这样的一个表,想存储每一种被交易的SKU(商品)的具体信息,需要获得商品的全部的信息(基本信息+交易信息)
这种表格的建立一般是公司开会制定的,不需要多余费解。
基本信息:
1. 编号 2. 所属订单号 3. 所属用户 4. 所有SKU_id 5. 所属商品名称 6. 所属商品单价 7. 订单交易该类商品的数量 8. 订单交易的创建时间(与改商品交易的时间一致) 9. 省份ID 10. 来源类型 11. 来源编号 12. 原始价格分摊 (指的是,在一个订单中,交易了很多商品,有一个总价格,我们需要这个总价格在该SKU商品上交易的金额,说白了就是:==需要知道订单中的这个商品的价格==,这个信息可以针对订单中的单个商品进行退款操作。 13. 购买价格分摊(指的是,当我们支付的时候,一次支付一个订单,我们需要知道支付订单中,这个商品实际花了多少钱) 14. 运费分摊 15. 优惠分摊
1.2 建表语句
create external table dwd_fact_order_detail (
`id` string COMMENT '明细编号-1',
`order_id` string COMMENT '订单号-2',
`user_id` string COMMENT '用户id-3',
`sku_id` string COMMENT 'sku商品id-4',
`sku_name` string COMMENT '商品名称-5',
`order_price` decimal(16,2) COMMENT '商品价格-6',
`sku_num` bigint COMMENT '商品数量-7',
`create_time` string COMMENT '创建时间-8',
`province_id` string COMMENT '省份ID-9',
`source_type` string COMMENT '来源类型-10',
`source_id` string COMMENT '来源编号-11',
`original_amount_d` decimal(20,2) COMMENT '原始价格分摊-12',
`final_amount_d` decimal(20,2) COMMENT '购买价格分摊-13',
`feight_fee_d` decimal(20,2) COMMENT '运费分摊-14',
`benefit_reduce_amount_d` decimal(20,2) COMMENT '优惠分摊-15'
) COMMENT '订单明细事实表表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_order_detail/'
tblproperties ("parquet.compression"="lzo");1.3 ODS实现DWD订单明细事实表
要想实现上述创建的表,先观察表结构
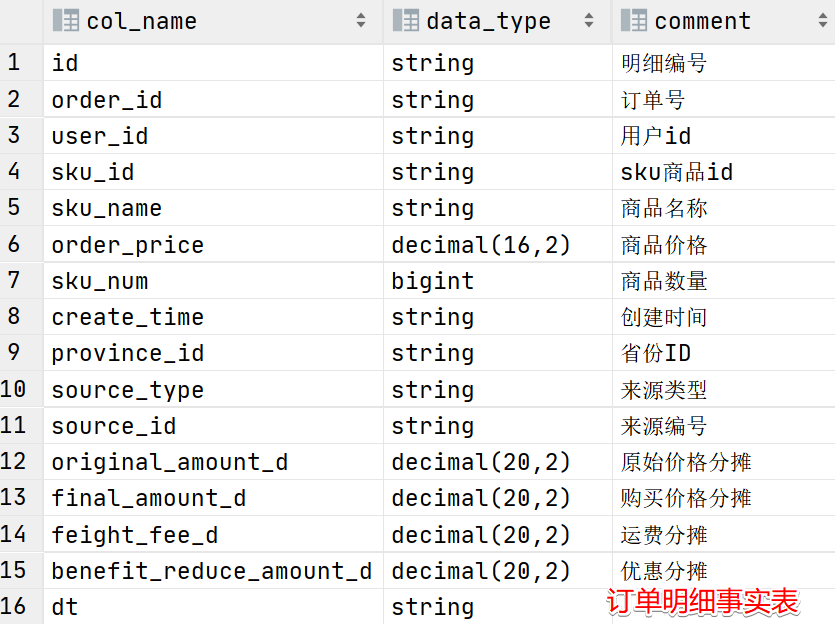
然后与ODS中的表一一比对可以发现表中的信息主要来源于两张ODS表格
ods_order_detail 与 ods_order_info(主要是提取一个省份ID,使用order_detail.order_id=order_info.id连接即可,使用普通的join即可)
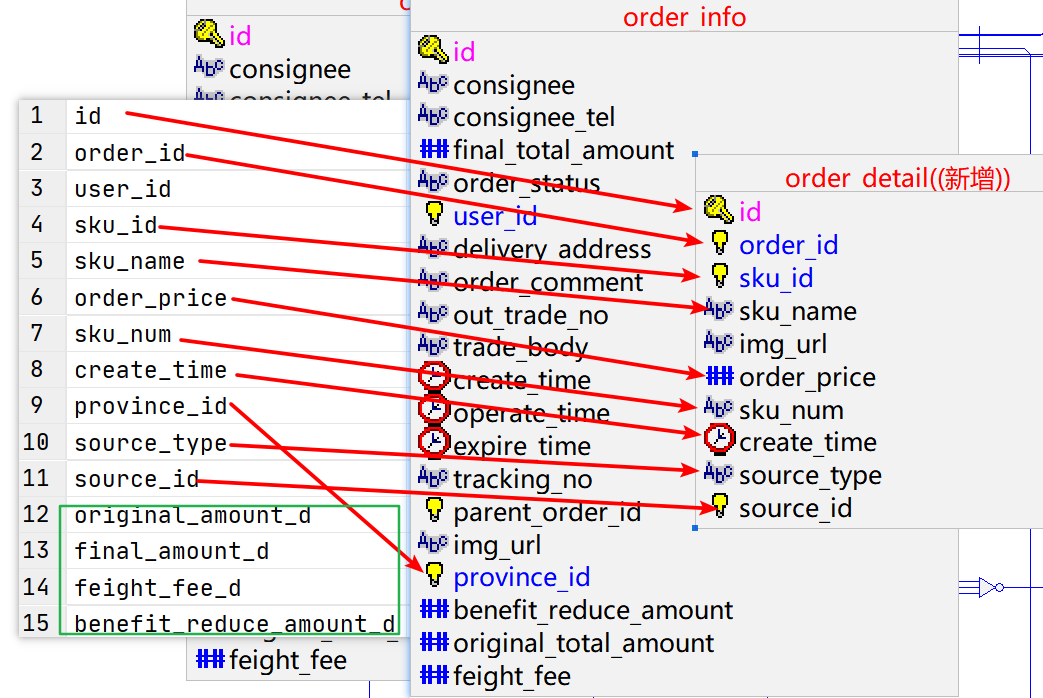
现在还有绿框中的几个条目没有解决,现在我们一一解析
首先是12号的original_amount_d,这是原始价格分摊,就是一个订单中的原始价格中的某一个SKU的所分摊的价格, 这个比较简单,使用order_detail表中的
order_price*sku_num --原始价格分摊,就是单价*数量然后是13号的final_amount_d,这是支付价格分摊,就是单个SKU在实际订单支付的金额中占据的价格
注意round(x,2),是保留两位小数的意思,因为在算比例的时候肯定会出现小数,而金钱肯定只能保留到两位小数(元角分)
所以这里保留两位小数
round(order_price*sku_num/original_total_amount*final_total_amount,2)--支付价格分摊
--单价*数量/原始订单总价*支付订单总价 == 支付订单总价*((单价*数量)/原始订单总价)接下来是14号的freight_fee_d,这是运费价格公摊,这个照葫芦画瓢的计算即可
--单价*数量/原始订单总价*总运费 == 总运费*((单价*数量)/原始订单总价)
round(order_price*sku_num/original_total_amount*freight_fee,2) --运费价格分摊接下来是15号的benefit_reduce_amount_d,这是优惠价格公摊,这个照葫芦画瓢的计算即可
--单价*数量/原始订单总价*总优惠 == 总优惠*((单价*数量)/原始订单总价)
round(order_price*sku_num/original_total_amount*benefit_reduce_amount,2) --优惠价格分摊1.4 初步填充
select
od.id,
od.order_id,
od.user_id,
od.sku_id,
od.sku_name,
od.order_price,
od.sku_num,
od.create_time,
od.source_type,
od.source_id,
od.order_price*od.sku_num original_amount_d,
round(od.order_price * od.sku_num/oi.original_total_amount*oi.final_total_amount,2) final_total_amount_d,--修改差值
round(od.order_price * od.sku_num/oi.original_total_amount*oi.feight_fee,2) feight_fee_d,
round(od.order_price * od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2) benefit_reduce_amount_d
from (select id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
create_time,
source_type,
source_id
from ods_order_detail--选择order_detail
where dt = '2020-06-14') od
join--join默认明细条目多,order_info是事务上增量及其更新,order_detail是增量表,这一般是一一对应的
(select id,
final_total_amount,
province_id,
benefit_reduce_amount,
original_total_amount,
feight_fee
from ods_order_info--选择order_info
where dt = '2020-06-14') oi--注意日期
on od.order_id = oi.id;--拼接条件,1.5 补差分析
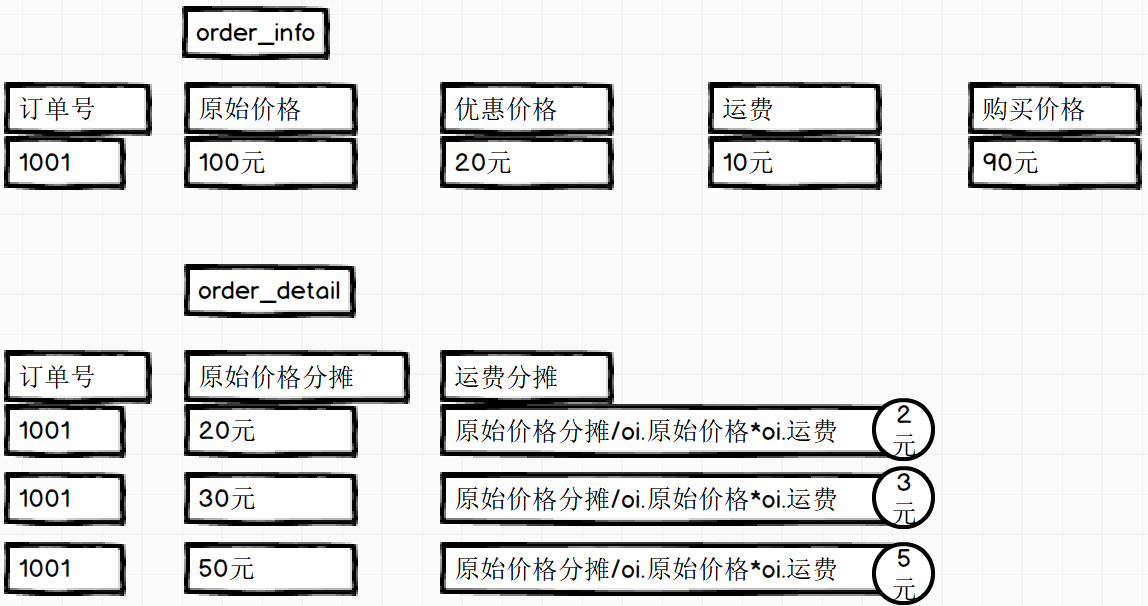
补差分析,要先明白差在哪里,这里借用老师的图
我们价格发生以下订单 购买三种商品 A 30 B 30 C 30
这时运费总计5元,需要知道,每个人round结果为(5 * (1/3)) = 1.67
select round(5*(1/3),2);--1.67
select round(5*(1/3),2);--1.67
select round(5*(1/3),2);--1.67
select 1.67*3;--5.01
--在round之后,产生了计算误差,如果每件商品依次退货的话,导致退货运费合计比原始运费要高,出现误差补差操作

--需要把补差完整,否则DWD中订单明细表的总运费与ODS的订单信息表的总运费无法对应
--全局思想
--思想,第一层1.4普通选择为分值,第二层1.5嵌套补差
--分值思想:分值主要是将每个订单里商品按照 (单品价格*单品数量/原总价)*[运费][支付价格][优惠价格]进行分粒度
--补差思想:订单总运费(feight_fee)-分摊后运费和(feight_fee_d_sum)+分粒度之后订单中第一个(row_number)SKU的运费(feight_fee_d)
--补差对象:订单里的第一个商品 over row_number
--补差对象属性:运费,支付价格,优惠价格
select
id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
create_time,
source_type,
source_id,
order_price*sku_num original_amount_d,
`if`(rn==1,final_total_amount-final_amount_d_sum+final_amount_d,final_amount_d) final_amount_d,
`if`(rn==1,feight_fee-feight_fee_d_sum+feight_fee_d,feight_fee_d) feight_fee_d,
`if`(rn==1,benefit_reduce_amount-benefit_reduce_amount_d_sum+benefit_reduce_amount_d,benefit_reduce_amount_d) benefit_reduce_amount_d
from
(select
od.id,
od.order_id,
od.user_id,
od.sku_id,
od.sku_name,
od.order_price,
od.sku_num,
od.create_time,
od.source_type,
od.source_id,
od.order_price*od.sku_num original_amount_d,
round(od.order_price * od.sku_num/oi.original_total_amount*oi.final_total_amount,2) final_amount_d,
round(od.order_price * od.sku_num/oi.original_total_amount*oi.feight_fee,2) feight_fee_d,
round(od.order_price * od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2) benefit_reduce_amount_d,
oi.original_total_amount,--定单定价
oi.feight_fee,--订单运费
oi.benefit_reduce_amount,--订单优惠
oi.final_total_amount,--订单最终支付
row_number() over (partition by od.order_id order by od.id) rn,
sum(round(od.order_price * od.sku_num/oi.original_total_amount*oi.final_total_amount,2)) over(partition by od.order_id) final_amount_d_sum,
sum(round(od.order_price * od.sku_num/oi.original_total_amount*oi.feight_fee,2)) over(partition by od.order_id) feight_fee_d_sum,
sum(round(od.order_price * od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2)) over(partition by od.order_id) benefit_reduce_amount_d_sum
from (select id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
create_time,
source_type,
source_id
from ods_order_detail
where dt = '2020-06-14') od
join
(select id,
final_total_amount,
province_id,
benefit_reduce_amount,
original_total_amount,
feight_fee
from ods_order_info
where dt = '2020-06-14') oi
on od.order_id = oi.id) t1
--一个三小时的sql,我吐了2. 优惠券领用事实表-累积型快照事实表
刚开始感觉这玩意,开始挺不好理解的,其实搞明白了之后除了繁琐点之外还是挺简单的
2.1 什么是累积型快照事实表
这里在理解的时候很容易被误导,然后老师讲一些乱七八糟的更乱了,所以这里需要整理性逆向理解
2.1.1 逆向分析
首先分析ods中的ods_coupon_use这张表中的字段
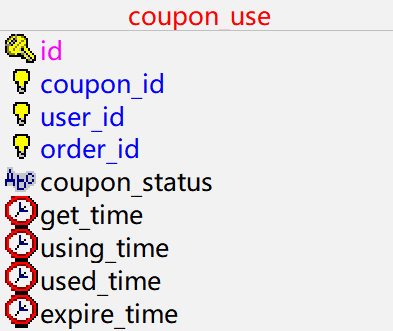
优惠券领用事实表存了啥?
简而言之:优惠券的基本信息与生命周期
可以看出字段中分别含有
get_time(获取时间)
using_time(下单时间)
used_time(支付时间)
优惠卷的生命周期:领取优惠卷->用优惠卷下单->优惠卷参与支付
分区 采用 优惠券领取时间 方便整理
这张表的好处: 方便我们以后统计优惠卷领取次数(统计含有获取时间的优惠券的个数)、优惠卷下单次数(统计含有下单时间的优惠券的个数)、优惠卷参与支付次数(统计拥有支付时间的次数)
新增及其变化表 :
新增可以理解为有一张新的优惠券被领用,
变化表理解为一张已经领用的优惠券进入新生命周期.
这时候要注意一点,就是向DWD表中导入数据时,ODS数据是比较新的,每天导入的都是新增及其变化的,然后我们可以把两张表拿出来做个图理解一下

图中可能说的不是很清楚,大体意思就是,新增及变化的表,新增的直接添加进DWD即可,关键是,变化的表,如何与来源的表进行合并,其实就是将DWD中的表拿出来然后与ODS中的表拿出来,FULL JOIN
这样取字段不为空的哪一个,其实写这个sql的关键难点在动态分区,因为分区是以get_time为分区的,所以需要现在DWD找到对应的分区的信息.同时还要注意格式(yyyy-MM-dd)
怎么找呢,就是先从ODS里找到所有get_time为 “2020-06-14”的
2.2 填充表
--核心思想,根据ODS表中的数据,找出所有的get_time,然后拉取DWD表中所有的分区名为get_time字段的分区,进行每条信息的逐一比对(FULL JOIN实现)
--在比对的过程中,如果是DWD表中有,而ODS中没有,说明这是以前的数据不修改
--如果DWD表中有,ODS中也有,说明这是优惠券存在变化的信息
--如果DWD表中没有,ODS中有,说明这是新增的优惠券领用信息
--整个过程注意动态分区
set hive.exec.dynamic.partition.mode=nonstrict;--设定非严格模式
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_coupon_use partition(dt)
select
nvl(new.id,old.id),
nvl(new.coupon_id,old.coupon_id),
nvl(new.user_id,old.user_id),
nvl(new.order_id,old.order_id),
nvl(new.coupon_status,old.coupon_status),
nvl(new.get_time,old.get_time),
nvl(new.using_time,old.using_time),
nvl(new.used_time,old.used_time),--nvl函数
date_format(nvl(new.get_time,old.get_time),'yyyy-MM-dd') dt--定义动态分区时间
from (select id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time,
dt
from ods_coupon_use
where dt='2020-06-14') new
full join
(select id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time,
dt
from dwd_fact_coupon_use
where dt in
(select
date_format(get_time,'yyyy-MM-dd')
from ods_coupon_use
where dt='2020-06-14')--拿出所有创建的时间与ODS新来的表对应的创建时间的表进行对应
) old--限定时间
on old.id = new.id--是不是每一张优惠券都有一个独立的ID3. 订单事实表-累积型快照事实表
3.1 分析
订单事实表存的什么?
首先是 订单的基本信息 : 编号 用户id 支付流水 运费 订单金额 .etc.
然后是订单生命周期:创建时间=>支付时间=>取消时间=>完成时间=>退款时间=>退款完成时间 (这部分展示出累积这个关键字的描述之处)
说白了就是订单事实表应该存储每一个订单的基本信息与其生命历程(生命历程需要变化,累积记录)
3.1.1 分析字段-基本字段
使用ods_order_info我们基本可以对应出大部分字段,但是还有一些状态信息跟活动id没有解决,状态信息的话采用ods_order_status_log就可以解决。活动ID比较好解决使用,使用下图与SQL解决(图中没有标出)
select
*
activity_order.activity_id --就添加了activity_id了
from
order_info oi
left join --这样的join方式保证了原始订单的保全性,但是将参加活动的activity_id添加上
activity_order ao
on
oi.id = ao.order_id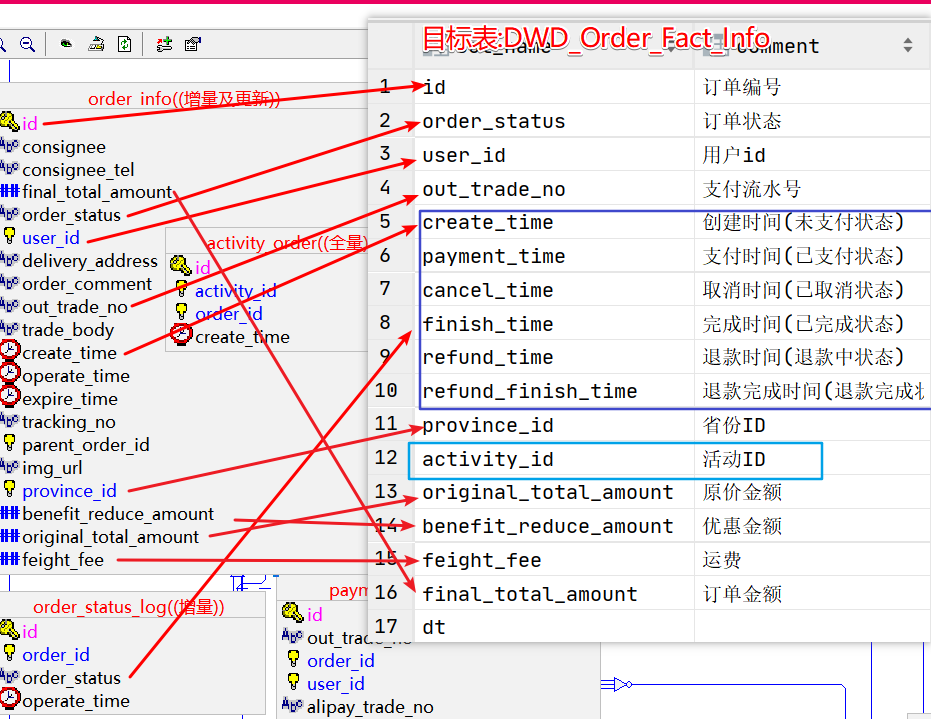 {zoom:10%}
{zoom:10%}
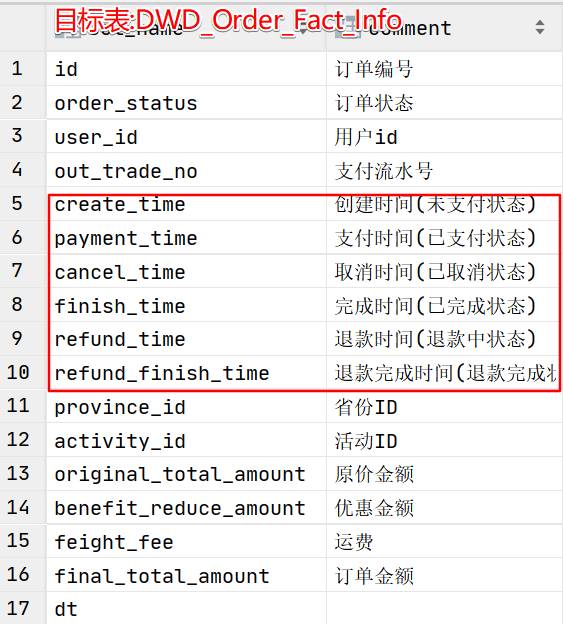
3.1.2 分析字段-状态字段
观察目的表,发现很多状态的时间这些字段不好获得,需要使用ods_order_status_log(增量)与ods_base_dic(特殊)join得到每个字段的状态
先观察ods_order_status(增量表)中字段
存在一些状态信息,这些状态信息呢,需要从ods_order_status中拉取,一些编号可以从字典表中对应,也可以join,这里就不搞了
select *from ods_order_status_log order by order_id;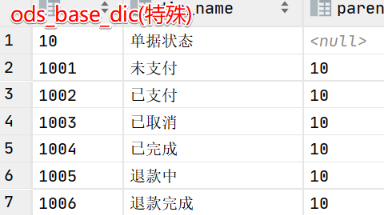
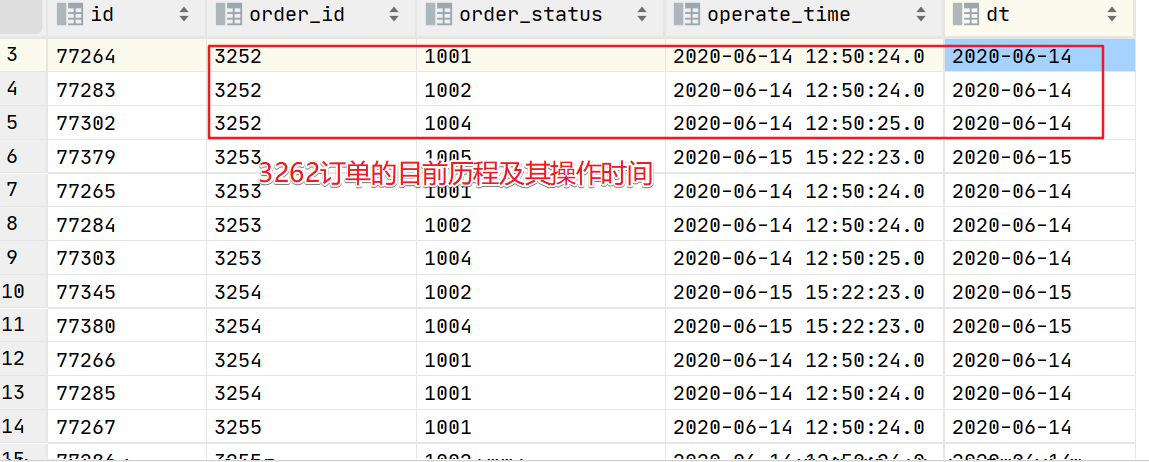
这样大体就可以分析得出了我们要向满足目的表,需要从以下表中拉取数据
- ods_order_info(基本信息)
- ods_order_status(订单生命周期)
- ods_activity_order(活动ID)
3.2 建表语句
create external table dwd_fact_order_info (
`id` string COMMENT '订单编号',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id',
`out_trade_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间(未支付状态)',
`payment_time` string COMMENT '支付时间(已支付状态)',
`cancel_time` string COMMENT '取消时间(已取消状态)',
`finish_time` string COMMENT '完成时间(已完成状态)',
`refund_time` string COMMENT '退款时间(退款中状态)',
`refund_finish_time` string COMMENT '退款完成时间(退款完成状态)',
`province_id` string COMMENT '省份ID',
`activity_id` string COMMENT '活动ID',
`original_total_amount` decimal(16,2) COMMENT '原价金额',
`benefit_reduce_amount` decimal(16,2) COMMENT '优惠金额',
`feight_fee` decimal(16,2) COMMENT '运费',
`final_total_amount` decimal(16,2) COMMENT '订单金额'
) COMMENT '订单事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_order_info/'
tblproperties ("parquet.compression"="lzo");3.2 填充语句
建完表后,我们可以根据字段分析进行sql的书写
这个sql可以说是比较长的,那我们即使明白了字段下面三张表中获取的,依然有一种无从下手的感觉
- ods_order_info(基本信息)
- ods_order_status(订单生命周期)
- ods_activity_order(活动ID)
没有关系,现在把目标表的字段订在右手边,然后开始思考三张表的sql关系,写一个简单的sql,后期可以进行修改,这个时候我一般会拿出来文档中的sql直接分析他的思路框架,复习一下,因为不够熟练.也不要紧了,主要是学会思想
整体简单思路分析:
dwd_info_fact_info 存储的当前的订单事实表(累积型快照事实表)
看流程图 ods_order_info(增量及更新)[==此处区别于新增及变化==] 增量及更新是原有数据不可更改,更新为新添加更新后数据(a1(dt=2020-06-14) >>> a12(dt=2020-06-15)),假设我们已经根据ods整合好了一张new table.
首先定义a具有累积也行,四个生命周期a1234 partition(create_time)
graph LR A[ods_6-14
一个订单a.12]-->B{与老表中同一个订单信息
n.order_id=o.order_id
比对方式 full_join} B--是a.1-->C[更新原有订单 a.1
nul a.12,a.1] B--否null-->D[直接新增订单 null
nul a.12,null] C-->E[overwrite >>
dt=a.12.create_time] D-->F[overwrite >>
dt=a.12.create_time]矛盾就转换为新表的整合与旧表的抽取
对应之后存在以下可能
--1
nvl(old,new)
--old = null 取新
--new = null 取旧
--然后取完之后按照动态分区,根据订单的创建的时间返回到各自的分区中
insert overwrite dwd_info_fact_info partition(dt)
select
*
date_format(create_time,yyyy-MM-dd)
from
...然后我们基本可以确认sql书写步骤
- 新表(ODS)
- 旧表(DWD)
- FULL JOIN
3.2.1 新表ODS的整合sql书写
思路继续从这三个表开始拓展,可以翻翻前面的字段分析
- ods_order_info(基本信息)(订单为粒度)
- ods_order_status(订单生命周期)(订单状态为粒度-需要转换粒度,难点)
- ods_activity_order(活动ID,left_join前面已经提及了)
--首先想明白粒度转换的必要性,如果不进行粒度转换,ods_order_status,则join之后基本信息ods_order_info会变成多条不好处理,这里进行粒度转换便于理解,目前我这里是按照文档中走的
--1.>>>>old表来源之一ods_order_status粒度增粗的sql
select
order_id,
str_to_map(concat_ws(",", collect_list(concat(order_status, "=", operate_time))),",","=") strmap
--str_to_map()一共传三个参数,第一个是str,第二个是每个kv之间的分隔符,第三个是k与v之间的分隔断
from ods_order_status_log
where dt = '2020-06-14'
group by order_id--粒度变粗
--2.>>>为了迎合第1步,将第一步的步骤进行二次包装,将一个订单的生命周期,在一条字段中显示出来
select
order_id,--用于join
tmp.strmap['1001'] create_time,--按照字典进行赋值
tmp.strmap['1002'] payment_time,
tmp.strmap['1003'] cancel_time,
tmp.strmap['1004'] finish_time,
tmp.strmap['1005'] refund_time,
tmp.strmap['1006'] refund_finish_time
from (
select
order_id,
str_to_map(concat_ws(",", collect_list(concat(order_status, "=", operate_time))),",","=") strmap
--str_to_map()一共传三个参数,第一个是str,第二个是每个kv之间的分隔符,第三个是k与v之间的分隔断
from ods_order_status_log
where dt = '2020-06-14'
group by order_id--粒度变粗
) tmp;
--3.>>>old表来源ods_order_info left join ods_activity_order
select oi.id,
oi.order_status,
oi.user_id,
oi.out_trade_no,
os.create_time,--还没有添加
os.payment_time,--1
os.cancel_time,--1
os.finish_time,--1
os.refund_time,--1
os.refund_finish_time,--1
oi.province_id,
oa.activity_id,
oi.original_total_amount,
oi.benefit_reduce_amount,
oi.feight_fee,
oi.final_total_amount,
oa.dt
from ods_order_info oi
left outer join--left join是将参加活动的商品加上活动id
ods_activity_order oa
on oi.id = oa.order_id;
--4.>>>三剑合璧
select oi.id,
oi.order_status,
oi.user_id,
oi.out_trade_no,
os.create_time,
os.payment_time,
os.cancel_time,
os.finish_time,
os.refund_time,
os.refund_finish_time,
oi.province_id,
oa.activity_id,
oi.original_total_amount,
oi.benefit_reduce_amount,
oi.feight_fee,
oi.final_total_amount,
oa.dt
from (select * from ods_order_info where dt = '2020-06-14') oi --ods_order_info
left outer join
(select * from ods_activity_order oa where dt = '2020-06-14') oa --ods_activity_order
on oi.id = oa.order_id
join(select
order_id,--用于join
tmp.strmap['1001'] create_time,
tmp.strmap['1002'] payment_time,
tmp.strmap['1003'] cancel_time,
tmp.strmap['1004'] finish_time,
tmp.strmap['1005'] refund_time,
tmp.strmap['1006'] refund_finish_time
from (
select
order_id,
str_to_map(concat_ws(",", collect_list(concat(order_status, "=", operate_time))),",","=") strmap
--str_to_map()一共传三个参数,第一个是str,第二个是每个kv之间的分隔符,第三个是k与v之间的分隔断
from ods_order_status_log
where dt = '2020-06-14'
group by order_id--粒度变粗
) tmp) os
on oi.id = os.order_id;3.2.2 旧表DWD的拉取sql书写
--旧表的拉取其实是相对简单的,根据新表的数据,拿出新表中所有的create_time,此时新表中的create_time应该是旧表拉取数据所寻找分区的重要依据,旧表应该拉取对应分区中的数据,方便对更新的数据进行对应补全
--这里的思路应该是直接使用ods_order_info,也就是重要三表中的主表,他包含了所有订单的create_time,其实我们订单状态的create_time也可以使用这个
--1. ods_order_info(旧表的拉取对应的分区使用这里面的create_time,找到分区数据)
--2. dwd_fact_order_info(找主数据)
select
id,--主数据
order_status,
user_id,
out_trade_no,
create_time,
payment_time,
cancel_time,
finish_time,
refund_time,
refund_finish_time,
province_id,
activity_id,
original_total_amount,
benefit_reduce_amount,
feight_fee,
final_total_amount
from dwd_fact_order_info
where dt in(
select
date_format(create_time,'yyyy-MM-dd')
from ods_order_info
where dt = '2020-06-14'--要导入是2020-06-14的数据,分区选择
)3.2.3 新表旧表FULL JOIN
直接合并了,这里要注意insert的理解,指的是把这些数据重新动态插入到新的分区或者是原来的分区,这一步虽然简单,但是底层做的工作也不少
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_order_info partition(dt)
select
nvl(new.id,old.id),
nvl(new.order_status,old.order_status),
nvl(new.user_id,old.user_id),
nvl(new.out_trade_no,old.out_trade_no),
nvl(new.create_time,old.create_time),
nvl(new.payment_time,old.payment_time),
nvl(new.cancel_time,old.cancel_time),
nvl(new.finish_time,old.finish_time),
nvl(new.refund_time,old.refund_time),
nvl(new.refund_finish_time,old.refund_finish_time),
nvl(new.province_id,old.province_id),
nvl(new.activity_id,old.activity_id),
nvl(new.original_total_amount,old.original_total_amount),
nvl(new.benefit_reduce_amount,old.benefit_reduce_amount),
nvl(new.feight_fee,old.feight_fee),
nvl(new.final_total_amount,old.final_total_amount),
date_format(nvl(new.create_time,old.create_time),'yyyy-MM-dd')
from (
select
oi.id,
oi.order_status,
oi.user_id,
oi.out_trade_no,
os.create_time,
os.payment_time,
os.cancel_time,
os.finish_time,
os.refund_time,
os.refund_finish_time,
oi.province_id,
oa.activity_id,
oi.original_total_amount,
oi.benefit_reduce_amount,
oi.feight_fee,
oi.final_total_amount,
oa.dt
from (select * from ods_order_info where dt = '2020-06-14') oi --ods_order_info
left outer join
(select * from ods_activity_order oa where dt = '2020-06-14') oa --ods_activity_order
on oi.id = oa.order_id
join(select
order_id,--用于join
tmp.strmap['1001'] create_time,
tmp.strmap['1002'] payment_time,
tmp.strmap['1003'] cancel_time,
tmp.strmap['1004'] finish_time,
tmp.strmap['1005'] refund_time,
tmp.strmap['1006'] refund_finish_time
from (
select
order_id,
str_to_map(concat_ws(",", collect_list(concat(order_status, "=", operate_time))),",","=") strmap
--str_to_map()一共传三个参数,第一个是str,第二个是每个kv之间的分隔符,第三个是k与v之间的分隔断
from ods_order_status_log
where dt = '2020-06-14'
group by order_id--粒度变粗
) tmp) os
on oi.id = os.order_id
) old --将旧表拿出来
full outer join --full join
(
select
id,
order_status,
user_id,
out_trade_no,
create_time,
payment_time,
cancel_time,
finish_time,
refund_time,
refund_finish_time,
province_id,
activity_id,
original_total_amount,
benefit_reduce_amount,
feight_fee,
final_total_amount
from dwd_fact_order_info
where dt in(
select
date_format(create_time,'yyyy-MM-dd')
from ods_order_info
where dt = '2020-06-14'--要导入是2020-06-14的数据
)
) new --将新表拿出来
on new.id = old.id --join条件


