Kylin_总结
1.Kylin的创建model
创建model是将数据仓库根据模型逐步创建出来
2.构建Cube的思考
Cube是一个计算的单元,通过拿取指定的字段,不同的维度交叉提前计算
重新理解度量值:所有的聚合函数,sum max min 都是为度量值准备的
3.Kylin的Cube构建的思考
我们是这样构建Cube的,使用了四个维度值,一个度量值
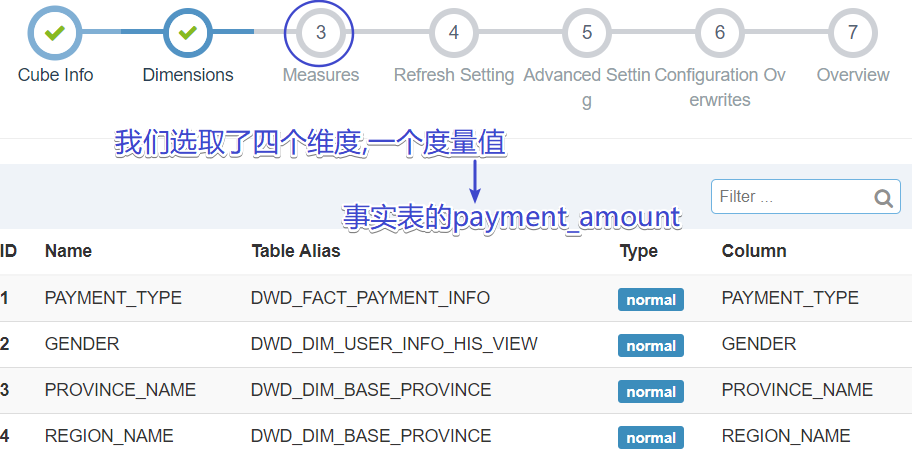
剩下的字段是用于join的

然后使用字段互相join,把所有的可能计算完毕

上图中,四个度量值产生了15中可能
其中构建的过程中可以设置一些参数,
起到筛选的作用
比如衍生维度,聚合组,强制维度
4.SQL查询的思考
因为在kylin的架构中,
关闭了与hive相连接的路由器
所以仅仅支持已经预算好的查询
同时还有一些苛刻的条件
比如
求不同省份的总支付金额
-- sql_1
select
province_id,
sum(payment_amount)
from dwd_fact_payment_info pay
join dwd_dim_base_province pro
on pay.province_id=pro.id
group by pay.province_id这个sql是完全没有问题的,但是再kylin中就目前的状态是完全无法执行的
然后按照下面状态修改
-- sql_2
select
pro.province_name,
sum(payment_amount)
from dwd_fact_payment_info pay
join dwd_dim_base_province pro
on pay.province_id=pro.id
group by pro.province_name--使用设定为维度的字段进行group_by发现程序就可以正常运行了,
同时,我们在join的时候将事实表与维度表的位置进行对换,如下
-- sql_3
select
pro.province_name,
sum(payment_amount)
from dwd_dim_base_province pro
join dwd_fact_payment_info pay
on pay.province_id=pro.id
group by pro.province_name--使用维度表的字段进行group_by然后程序还是报错,是不是哭了
其实–sql_3不能运行是可以理解的
SELECT
`pay`.`PAYMENT_TYPE`
,`user`.`GENDER`
,`pro`.`PROVINCE_NAME`
,`pro`.`REGION_NAME`
,`pay`.`PAYMENT_AMOUNT`
FROM `GMALL`.`dwd_fact_payment_info` as pay
INNER JOIN `GMALL`.`dwd_dim_user_info_his_view` as `user`
ON `pay`.`USER_ID` = `user`.`ID`
INNER JOIN `GMALL`.`dwd_dim_base_province` as `pro`
ON `pay`.`PROVINCE_ID` = `pro`.`ID`
WHERE 1=1这个是cube创建时自带的join语句,人家规定你必须事实表join维度表才可以进行查询,不能倒过来
那sql_1到底是什么问题造成的呢,
其实发现这种sql是有迹可循的,我们在创建cube的过程中,仅仅使用四个维度,同时使用三个关键字段,我们在查询的时候同样只能查询维度字段,而关联字段其实并不是存在于表中
也就是说,我们只能查出province_name(维度表dwd_dim_base_province中指定的维度),而不能查出province_id,这是关联字段,因此报错
5.定时开启Kylin脚本
#!/bin/bash
#从第1个参数获取cube_name
cube_name=$1
#从第2个参数获取构建cube时间
if [ -n "$2" ]
then
do_date=$2
else
do_date=`date -d '-1 day' +%F`
fi
#获取执行时间的00:00时间戳
start_date_unix=`date -d "$do_date 08:00:00" +%s`
#秒级时间戳变毫秒级
start_date=$(($start_date_unix*1000))
#获取执行时间的24:00的时间戳
stop_date=$(($start_date+86400000))
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' -d '{"startTime":'$start_date', "endTime":'$stop_date', "buildType":"BUILD"}' http://hadoop102:7070/kylin/api/cubes/$cube_name/build然后把这个脚本交给azkaban定时运行,是==restFulAPI==
查看文档
注意密码使用basic加密
注意时区
6.使用DataGrip连接Kylin
JDBC驱动
在option里加上驱动
jdbc:kylin://hadoop102:7070/FirstProject”
//Kylin的用户名
String KYLIN_USER = “ADMIN”;
//Kylin的密码
String KYLIN_PASSWD = “KYLIN”;
7.zeppelin
启动:bin/zeppelin-daemon.sh start
修改8080端口步骤
来到conf目录下
cp zepplin-site.xml.template zepplin-site.xml
//然后修改端口号即可
78788.粒度问题的解析
8.1 测试一
手写sql
需求:查询不同地区的总支付金额
select
b.region_name,
sum(payment_amount)
from dwd_fact_payment_info a
join dwd_dim_base_province b
on a.province_id=b.id
group by b.region_name结果:
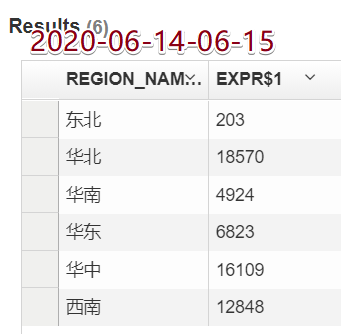
脚本走一波
kylin_cube_build.sh payment_cube 2020-06-15
--cube_name dt继续查询发现结果变了
select
b.region_name,
sum(payment_amount)
from dwd_fact_payment_info a
join dwd_dim_base_province b
on a.province_id=b.id
group by b.region_name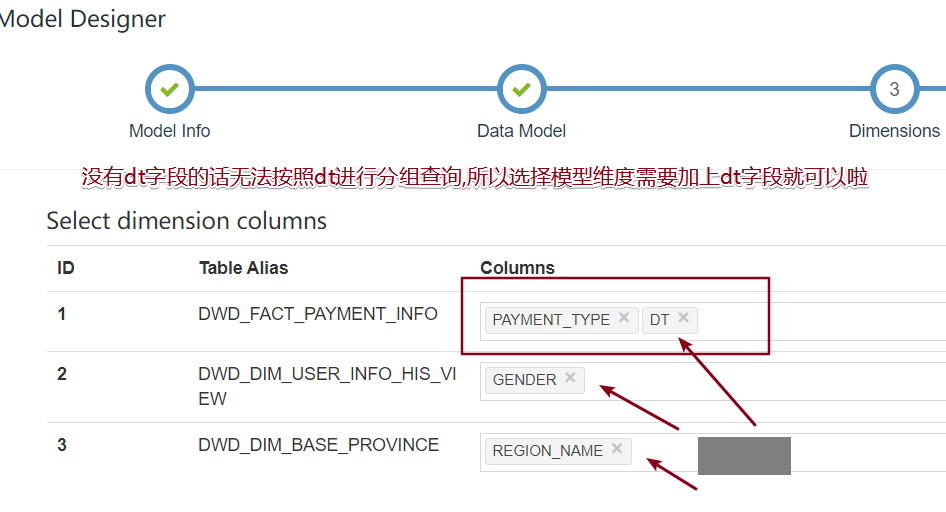
问题抛出,想查6-14号怎么办
select
b.region_name,
sum(payment_amount)
from dwd_fact_payment_info a
join dwd_dim_base_province b
on a.province_id=b.id
where dt = '2020-06-14'
group by b.region_name报错,为什么
8.2 测试二
select
b.region_name,
sum(payment_amount)
from dwd_fact_payment_info a
join dwd_dim_base_province b
on a.province_id=b.id
where dt = '2020-06-14'
group by b.region_name就是这样
9.kylin的关闭
kylin主程序
bin/kylin.sh stop/start
http://hadoop102:7070/kylin
--webUI
--用户名为:ADMIN,密码为:KYLINbin/stop-hbase.shhttp://hadoop102:16010](http://linux01:16010)
--HBASE webUI 


