summary
主要针对一些flink的DataStreamAPI的需求简单实现,如分时PV UV,分时TopN,广告推广的恶意点击监控,
订单下单未支付监控与实时对账功能(join与connect方式)
需求1-ClickCountTopN
每隔5分钟输出最近一小时内点击量最多的前N个商品
解决方案
1 = 抽取出业务时间戳,告诉Flink框架基于业务时间做窗口
2 = 过滤出点击行为数据
3 = 添加滑动窗口(1h,5min),添加窗口结束时间
4 = 按照窗口结束时间分组,添加入状态,添加定时器,窗口结束之后进行计算程序
1.keyby(id) = 按key分组
2.timeWindow(Time.hours(1), Time.minutes(5)) = 开窗
3.aggregate(new aggre(),new windowfunc())->itemcount(+windowend)
= 获取window结束时间
4.keyby(windowtime)
5.process()->value->list状态+定时(windowend+1)->ontimer(toArray->排序->out.collect())
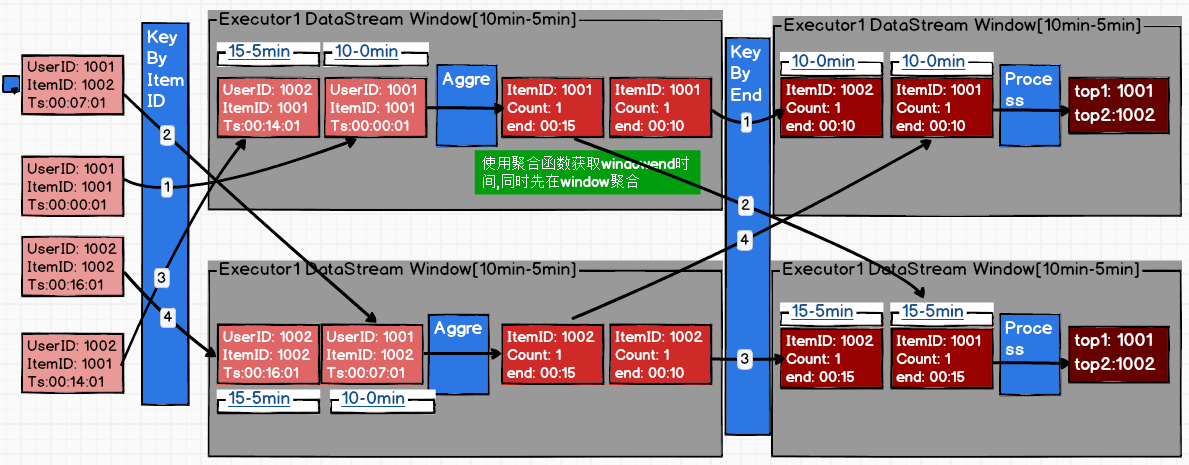
需求2-基于服务器log页面浏览量统计
2.1 每隔5秒,输出最近10分钟内访问量最多的前N个URL
其中包含乱序数据的处理
目标 = HotUrlAPP
程序
0.指定事件时间语义,
1.keyby(id) = 按key分组
2.timeWindow(Time.hours(1), Time.minutes(5)) = 开窗,指定迟到数据(60秒)
3.aggregate(new aggre(),new windowfunc())->itemcount(+windowend)
= 获取window结束时间
4.keyby(windowtime)
5.process()->value->map状态+
6.定时(windowend+1)->ontimer(toArray->排序->out.collect())
7.定时(windowend+60)->ontimer(mapstate.clear())
需求3 基于埋点日志数据的网络流量统计
3.1 网站总浏览量(PV)的统计
网站用PV
思路:
用户行为日志->pv
pv->new tuple()
new tuple()->keyby(0)
keyby(0)->timewindow(1h)
timewindow(1h)->sum()->print()
注意:
这样的keyBy(0)是非常容易产生数据倾斜的,根据本身自主的key来讲,很容易产生数据倾斜

数据倾斜解决方案
- 在key前面加随机数
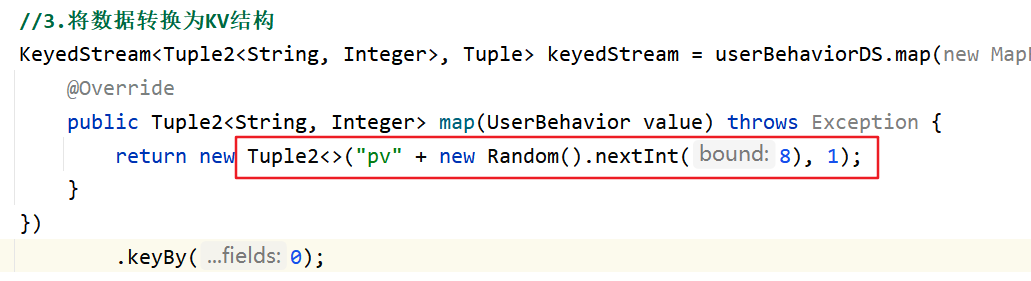
- 添加窗口时间,存在window的话使用
userBehavior
.map()
.keyBy(0)
.timeWindow()
.aggregate(new aggre(),new window())//windowFunc上加上window时间
.keyBy(windowEnd)//根据时间分组
.process(new PvCount())
//定时在窗口结束时,使用定时器清空状态总结:
对于简单的==网站的每小时总PV业务需求==来讲,很容易产生数据倾斜的问题,一般来讲,使用两步来进行解决,首先将PV的key字段加上随机数解决倾斜问题
这样将数据发送到不同的executor进行开窗处理,然后按照windowend重新分配
3.2 网站独立访客数(UV)的统计(去重计算)
另外一个统计流量的重要指标是网站的独立访客数(Unique Visitor,UV)。UV指的是一段时间(比如一小时)内访问网站的总人数,1天内同一访客的多次访问只记录为一个访客。
通过IP和cookie一般是判断UV值的两种方式。
当客户端第一次访问某个网站服务器的时候,网站服务器会给这个客户端的电脑发出一个Cookie,通常放在这个客户端电脑的C盘当中。
在这个Cookie中会分配一个独一无二的编号,这其中会记录一些访问服务器的信息,如访问时间,访问了哪些页面等等。
当你下次再访问这个服务器的时候,服务器就可以直接从你的电脑中找到上一次放进去的Cookie文件,并且对其进行一些更新,但那个独一无二的编号是不会变的。
当然,对于UserBehavior数据源来说,我们直接可以根据userId来区分不同的用户。
需求4 市场营销的监控与统计
4.1 App市场推广统计
每隔5秒钟统计最近一个小时按照渠道的推广量。
public class MarketBehaviorSource implements ParallelSourceFunction<MarketUserBehavior> {
// 是否运行的标识位
private Boolean running = true;
// 定义用户行为和推广渠道的集合
private List<String> behaviorList = Arrays.asList("CLICK", "DOWNLOAD", "INSTALL", "UNINSTALL");
private List<String> channelList = Arrays.asList("app store", "wechat", "weibo", "tieba");
// 定义随机数发生器
private Random random = new Random();
@Override
public void run(SourceFunction.SourceContext<MarketUserBehavior> ctx) throws Exception {
while(running){
// 随机生成所有字段
Long id = random.nextLong();
String behavior = behaviorList.get(random.nextInt(behaviorList.size()));
String channel = channelList.get(random.nextInt(channelList.size()));
Long timestamp = System.currentTimeMillis();
// 发出数据
ctx.collect(new MarketUserBehavior(id, behavior, channel, timestamp));
Thread.sleep(100L);
}
}
@Override
public void cancel() {
running = false;
}
}使用典型的分组开窗,加windowend时间,然后聚合统计广告推送次数
4.2 广告点击黑名单监控

需求5 恶意登录监控(CEP)
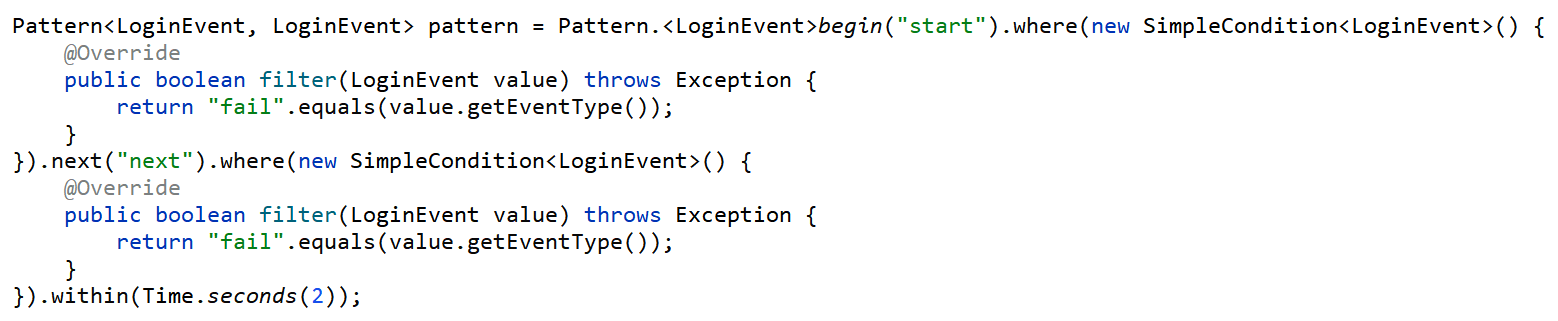
升级版
循环模式+严格近邻

需求6 订单支付实时监控
6.1 15分钟内未支付订单监控
在15分钟内,事件“create”与“pay”非严格紧邻

触发侧输出流

测输出流函数与主流函数

使用状态方程思路
思路:
keyBy(OrderEvent::getOrderId);
keyedStream.process(new OrderTimeOutProcessFunc());
如果遇见create就创建定时器,然后15分钟内遇见pay就删除定时器,否则使用定时器的侧输出流输出超时订单
6.2 实时对账功能的实现
将支付与到账进行实时对账,防止出现金融问题
对于订单支付事件,用户支付完成其实并不算完,我们还得确认平台账户上是否到账了。而往往这会来自不同的日志信息,所以我们要同时读入两条流的数据来做合并处理。这里我们利用connect将两条流进行连接,然后用自定义的CoProcessFunction进行处理。

思路:
对两个流进行处理,一个是ReceiptEvent
一个事OrderEvent
使用connect进行流连接
-->对于order事件
然后判断支付数据(orderrEvent)
如果receipt = null -->支付数据先到,到账数据还没到,注册定时器,将orderEevent放入状态
如果receipt != null -->到账数据先到,删除到账先到的[定时器],输出,[清空]流水号状态
-->对于receipt事件
如果order != null -->正常数据 删除order定时器 清空状态输出
如果order = null -->到账数据先到/注册网络延迟定时器/等待下单数据 将receipt放入状态
实时对账功能的实现(join)
flink只有innerjoin

//3.按照事务ID分组之后进行Join
SingleOutputStreamOperator<Tuple2<OrderEvent, ReceiptEvent>> result = orderEventDS.keyBy(OrderEvent::getTxId)
.intervalJoin(receiptEventDS.keyBy(ReceiptEvent::getTxId))
.between(Time.seconds(-3), Time.seconds(5))
.process(new PayReceiptJoinFunc());
双流join或者connect/join
同时要注意watermark的跳变
==问题== 双流join解决了watermark跳变问题么
当出现采集数据出现网络动荡的时候



