Hadoop入门
学习目标:
- 了解大数据的概念以及应用场景和发展前景(这部分还是会讲故事即可)
- 初步掌握大数据部门业务分析流程以及完整的大数据部门的组织架构(还是了解讲故事…)
- 通俗易懂的说明白Hadoop的概念以及发展历史
- 掌握Hadoop的前后的版本迭代更新以及Hadoop的优势
- 重点理解Hadoop框架的三大组成部分,并准确的表述各自的作用
- 掌握大数据生态的概念
- 熟练操作Hadoop运行环境的搭建(重点掌握)
- 熟练掌握Hadoop的运行模式(重点掌握)
- 掌握Hadoop2.x和Hadoop3.x版本的差异
- 能够对Hadoop的源码进行编译
- 掌握常见的错误和问题(重点)
一、大数据概论
前言:这部分主要讲解的就是大数据的概念,以及大数据的应用领域和发展前景,要求大家能够用自己的话去描述,讲给别人听即可!
1.大数据的发展史
In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log,they didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but formore systems of computers.
—Grace Hopper2.大数据的概念
大数据(big data),IT行业术语,是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
简单的讲 大数据 就是海量数据,我们想要利用这海量数据,必然要对它进行存储 ,然后又想让其实现价值,必须得通过 分析计算 得到结果,而分析计算也不能没有时间限制,那就得在合理的时间内分析计算。最后一句话就是 大数据技术就是来完成海量数据的存储以及对海量数据在合理时间内进行分析运算的
最小的基本单位是bit,按顺序给出所有单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB,它们按照进率1024(2的十次方)来计算:
8bit= 1Byte
1KB= 1,024 Bytes
1MB= 1,024 KB = 1,048,576 Bytes
1GB= 1,024 MB = 1,048,576 KB
1TB= 1,024 GB = 1,048,576 MB
1PB= 1,024 TB = 1,048,576 GB
1EB= 1,024 PB = 1,048,576 TB
1ZB= 1,024 EB = 1,048,576 PB
1YB= 1,024 ZB = 1,048,576 EB
1BB= 1,024 YB = 1,048,576 ZB
1NB= 1,024 BB = 1,048,576 YB
1 DB = 1,024 NB = 1,048,576 BB
3.大数据的特点
3.1大量(Volume)
想要贴近大数据的概念,必然要求海量数据,用量化的单位来描述的话至少也得PB级别的起步。
3.2高速(Velocity)
所谓的高速是指海量数据产生的速度是非常快的,例如 天猫双十一 大约1分钟左右成交100亿的,100亿背后所涉及的数据可想而知。同时数据产生速度的也要求我们对数据的处理的效率要跟上节奏才可以。
3.3多样(Variety)
多样是指数据的体现形式是多样化的,大体分为三种形式 结构化数据 半结构化数据 非结构化化数据,这些所说的基本上都是原始数据,我们将来要想地数据更高效的运算都会对原始数据进行清洗。
3.4低价值密度(Value)
在通常情况下,面对海量数据,往往我们需要的可能只是其中的一小部分,这就是说 价值密度的高低和数据总量是成反比的 这也是大数据比较显著的一个特点,所以 高效快速的对有价值的数据进行“提纯” 成为目前大数据领域一个攻坚破阻的难题。
4.大数据的应用场景
本章节主要了解大数据的真实应用场景和领域。这部分大家作为了解即可,推荐下面一片文章作为参考!
https://www.jianshu.com/p/bb989c2fbc76
5.大数据的发展前景
大数据行业的前景毋庸置疑是非常好的,从国家政策的推动再到行业的人才缺口以及未来的发展趋势都让大数据成为一个很有前途的专业。但是还是要求大家稳扎稳打 技术到家 才能翻江倒海!
6.大数据部门业务流程分析
本小节主要介绍在工作当中我们将来完成一个项目的业务流程,我们大数据的工作在哪一环节崭露头角!我们大数据主要任务就是根据具体的需求对数据进行存储和分析运算,最后获取想要的数据结果。
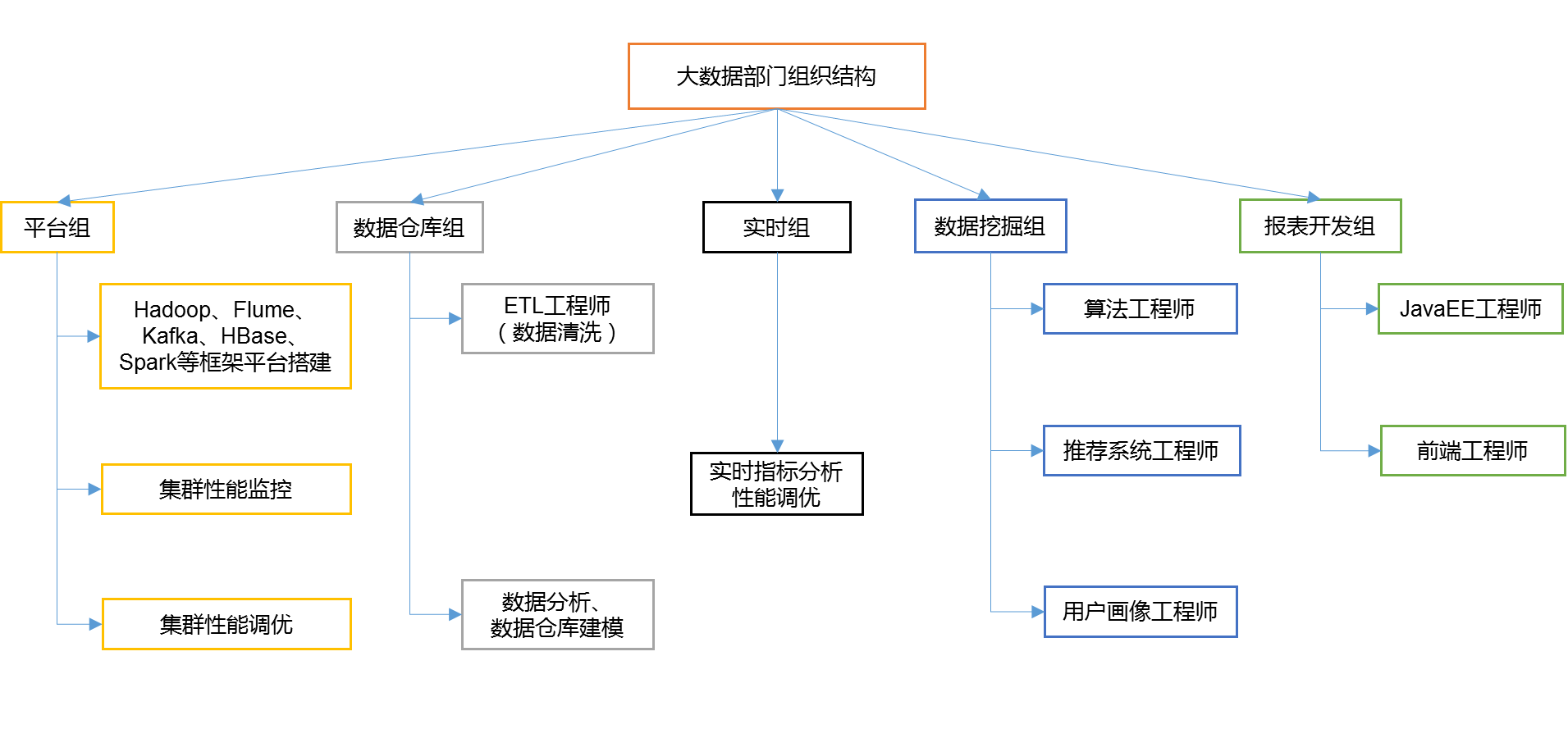
7.大数据部门组织结构(重点)
这一小节主要阐述一个公司通常大数据部门的智能分布,可以参考下图:
二、从Hadoop框架讨论大数据生态
1. Hadoop的概念
理解Hadoop是什么要从两个层面去入手:
1.1 狭义:Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。它的核心组件有:
HDFS(分布式文件系统):解决海量数据存储
YARN(作业调度和集群资源管理的框架):解决资源任务调度
MAPREDUCE(分布式运算编程框架):解决海量数据计算

1.2 广义:广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
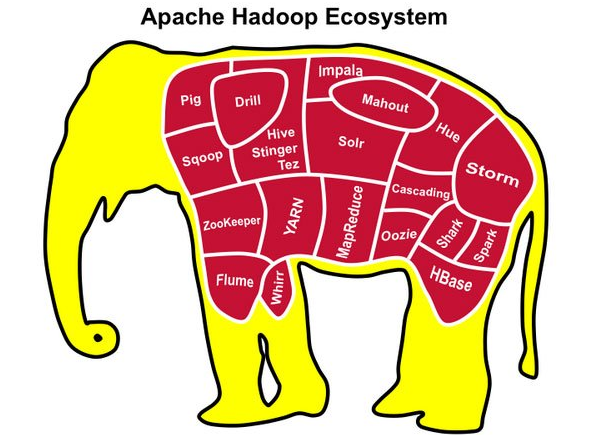
当下的Hadoop已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非Apache主管的项目,这些项目对HADOOP是很好的补充或者更高层的抽象。比如:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于HADOOP的分布式数据仓库,提供基于SQL的查询数据操作
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
OOZIE:工作流调度框架
Sqoop:数据导入导出工具(比如用于mysql和HDFS之间)
FLUME:日志数据采集框架
IMPALA:基于hive的实时sql查询分析
2. Hadoop的发展史

2002年10月,Doug Cutting和Mike Cafarella创建了开源网页爬虫项目Nutch。
2003年10月,Google发表Google File System论文。
2004年7月,Doug Cutting和Mike Cafarella在Nutch中实现了类似GFS的功能,即后来HDFS的前身。
2004年10月,Google发表了MapReduce论文。
2005年2月,Mike Cafarella在Nutch中实现了MapReduce的最初版本。
2005年12月,开源搜索项目Nutch移植到新框架,使用MapReduce和NDFS在20个节点稳定运行。
2006年1月,Doug Cutting加入雅虎,Yahoo!提供一个专门的团队和资源将Hadoop发展成一个可在网络上运行的系统。
2006年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
2006年3月,Yahoo!建设了第一个Hadoop集群用于开发。
10.2006年4月,第一个Apache Hadoop发布。
11.2006年11月,Google发表了Bigtable论文,激起了Hbase的创建。
12.2007年10月,第一个Hadoop用户组会议召开,社区贡献开始急剧上升。
13.2007年,百度开始使用Hadoop做离线处理。
14.2007年,中国移动开始在“大云”研究中使用Hadoop技术。
15.2008年,淘宝开始投入研究基于Hadoop的系统——云梯,并将其用于处理电子商务相关数据。
16.2008年1月,Hadoop成为Apache顶级项目。
17.2008年2月,Yahoo!运行了世界上最大的Hadoop应用,宣布其搜索引擎产品部署在一个拥有1万个内核的Hadoop集群上。
18.2008年4月,在900个节点上运行1TB排序测试集仅需209秒,成为世界最快。
19.2008年8月,第一个Hadoop商业化公司Cloudera成立。
20.2008年10月,研究集群每天装载10TB的数据。
21.2009 年3月,Cloudera推出世界上首个Hadoop发行版——CDH(Cloudera’s Distribution including Apache Hadoop)平台,完全由开放源码软件组成。
22.2009年6月,Cloudera的工程师Tom White编写的《Hadoop权威指南》初版出版,后被誉为Hadoop圣经。
23.2009年7月 ,Hadoop Core项目更名为Hadoop Common;
24.2009年7月 ,MapReduce 和 Hadoop Distributed File System (HDFS) 成为Hadoop项目的独立子项目。
25.2009年8月,Hadoop创始人Doug Cutting加入Cloudera担任首席架构师。
26.2009年10月,首届Hadoop World大会在纽约召开。
27.2010年5月,IBM提供了基于Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。
28.2011年3月,Apache Hadoop获得Media Guardian Innovation Awards媒体卫报创新奖
29.2012年3月,企业必须的重要功能HDFS NameNode HA被加入Hadoop主版本。
30.2012年8月,另外一个重要的企业适用功能YARN成为Hadoop子项目。
31.2014年2月,Spark逐渐代替MapReduce成为Hadoop的缺省执行引擎,并成为Apache基金会顶级项目。
2017年12月,Release 3.0.0 generally available
3. Hadoop三大发行版本
3.1 Apache
企业实际使用并不多。最原始(基础)版本。这是学习hadoop的基础。
3.2 cloudera
对hadoop的升级,打包,开发了很多框架。flume、hue、impala都是这个公司开发
2008 年成立的 Cloudera 是最早将 Hadoop 商用的公司,为合作伙伴提 供 Hadoop 的商用解决方案,主要是包括支持,咨询服务,培训。
2009年Hadoop的创始人 Doug Cutting也加盟 Cloudera公司。Cloudera 产品主要 为 CDH,Cloudera Manager,Cloudera Support
CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全 性,稳定性上有所增强。
Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署 好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即 是对Hadoop的技术支持。
Cloudera 的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大 数据的Impala项目。
3.3 Hortonworks
2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建
公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工 程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop 80%的代码。
雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任
Hortonworks的首席执行官。
Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开 源的产品,HDP除常见的项目外还包含了Ambari,一款开源的安装和管理系统
HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook 开源的Hive中
。Hortonworks的Stinger开创性地极大地优化了Hive项目。Hortonworks为入门提 供了一个非常好的,易于使用的沙盒。
Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能 够在包括Windows Server和Windows Azure在内的Microsoft Windows平台上本地 运行。定价以集群为基础,每10个节点每年为12500美元。
4. Hadoop的优势
4.1 高可靠性
Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
4.2 高可扩展性
在集群间分配任务数据,可方便的扩展数以千计的节点。
4.3 高效性
在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4.4 高容错性
能够自动将失败的任务重新分配。
5. Hadoop框架组成
Hadoop是一个能够对大量数据进行分布式处理的软件框架,以一种可靠、高效、可伸缩的方式进行数据处理,其有许多元素构成,以下是其组成元素:
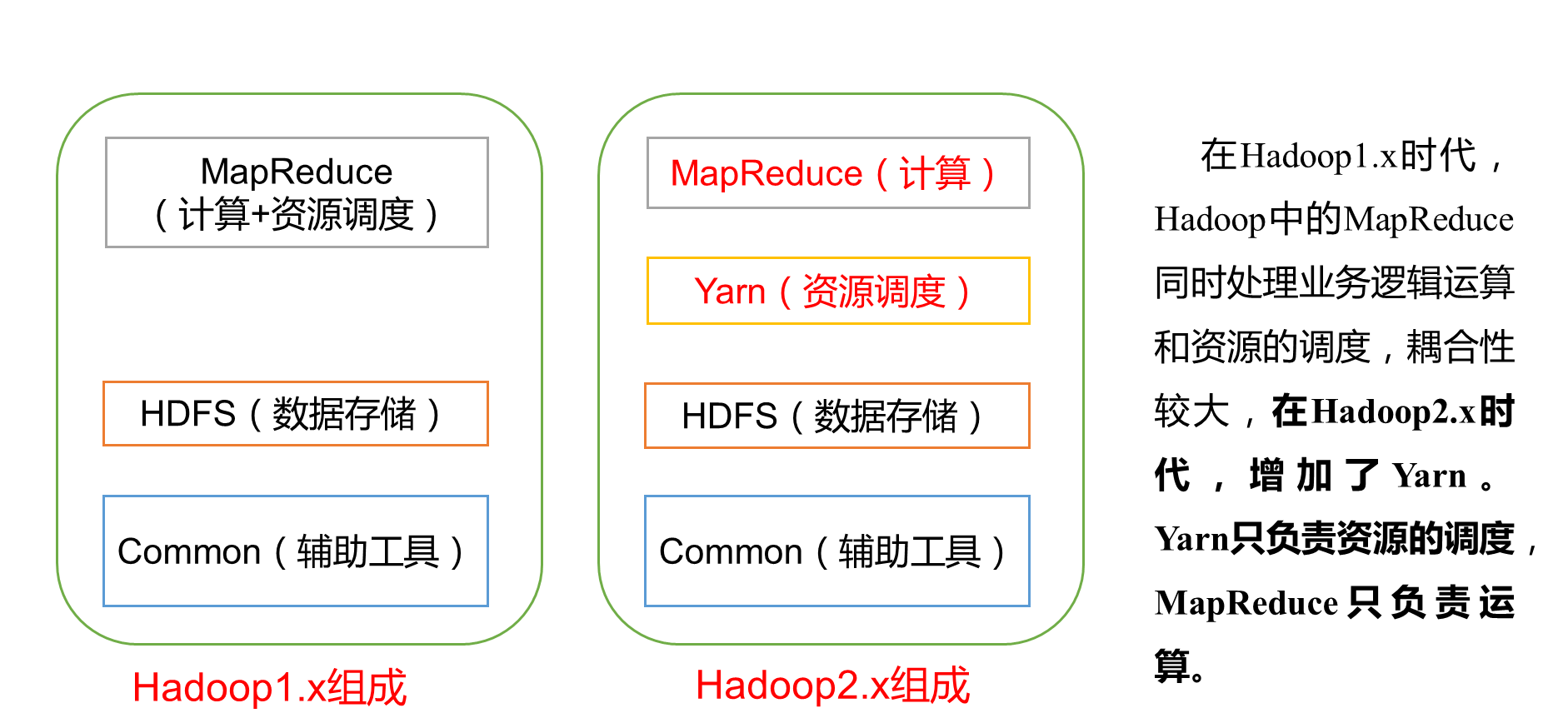
注意: 通过上图我们要掌握的重点是Hadoop是由核心的三大组件构成的,在hadoop1.x的版本中 只有两大组件分别是 HDFS(负责文件的存储)**和MapReduce(负责文件的计算和资源调度)** 。后来在hadoop2.x的时候出于架构的解耦考虑以及让 资源调度 工作能更加灵活多样化就把 原来MapReduce中的负责资源调度的功能剥离出来 单独形成 Yarn 这个核心组件。
5.1HDFS理论概述
HDFS: Hadoop Distributed File System(hadoop分布式文件系统)
注意: 本小节主要是从理论的角度先去理解HDFS的概念,HDFS中还包含很多概念我们逐个来分析理解。
1.HDFS的特点:
1. 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
2. 运行在廉价的机器上。
3. 适合大数据的处理。HDFS默认会将文件分割成block,64M为1个block。
然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很 重。2.在HDFS中有三个重要的角色相互协调工作,分别是NameNode SecondaryNameNode DataNode
1.NameNode Master节点,大领导。
-- 管理数据块映射;
-- 处理客户端的读写请求;
-- 配置副本策略;
-- 管理HDFS的名称空间。
-- namenode 内存中存储的是 = fsimage + edits。
其中fsimage元数据镜像文件(文件系统的目录树),edits元数据的操作日志(针对文件系统做的修改操 作记录)
总之:NameNode很重要,在海量数据的存储和管理,NameNode就相当于是所有数据的描述或者指针,有了它才能进一步操作真实数据。
2.SecondaryNameNode 它是个小弟,分担大哥NameNode的工作量。
-- SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再 发送给namenode。减少namenode的工作量。
-- NameNode的冷备份。
3.DataNode 真实数据的存储位置
-- 存储client发来的数据块block;
-- 执行数据块的读写操作。
5.2 YARN架构概述
本小节主要了解YARN架构中重要的几个 组件。本次接触YARN不要求掌握其本质原理,只要求混个脸熟,大概了解YARN的作用以及组成部分,为后面的学习建立基础。
1.为什么要用YARN?
首先我们要知道的是在Hadoop1.x时代 是没有YARN的,那时候所有的数据计算以及计算过程的任务分配和资源调度都是在MapReduce中进行的,这样存在很多问题和隐患,典型的就是JobTracker容易存在单点故障和JobTracker负担重,既要负责资源管理,又要进行作业调度;当需处理太多任务时,会造成过多的资源消耗。所以在Hadoop2.x的时候,推出了YARN这套系统,其主要目的就是将Hadoop中的资源调度功能独立的分离出来,这样更方便扩展,也能高效合理的调度资源。
2.YARN中的几大角色
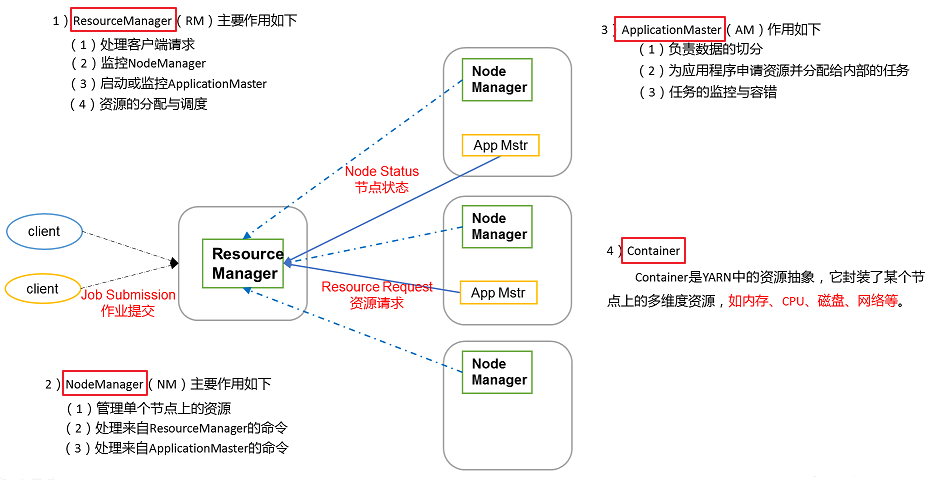
– ResourceManager
YARN 分层结构的本质是 ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排给基础 NodeManager(YARN 的每节点代理)。ResourceManager 还与 ApplicationMaster 一起分配资源,与 NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
总的来说,RM有以下作用:
1)处理客户端请求
2)启动或监控ApplicationMaster 3)监控NodeManager
4)资源的分配与调度 – NodeManager
ApplicationMaster 管理在YARN内运行的每个应用程序实例。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会带来基于手头任务的新资源类型(比如图形处理单元或专用处理设备)。从 YARN 角度讲,ApplicationMaster 是用户代码,因此存在潜在的安全问题。YARN 假设 ApplicationMaster 存在错误或者甚至是恶意的,因此将它们当作无特权的代码对待。
总的来说,AM有以下作用:
1)负责数据的切分 2)为应用程序申请资源并分配给内部的任务
3)任务的监控与容错
– ApplicationMaster
NodeManager管理YARN集群中的每个节点。NodeManager 提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。MRv1 通过插槽管理 Map 和 Reduce 任务的执行,而 NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。
总的来说,NM有以下作用:
1)管理单个节点上的资源
2)处理来自ResourceManager的命令
3)处理来自ApplicationMaster的命令 – Container
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
总的来说,Container有以下作用:
1)对任务运行环境进行抽象,封装CPU、内存等多维度的资源以及环境变量、启动命令等任务运行相关的信息总结:要使用一个 YARN 集群,首先需要一个包含应用程序的客户的请求。ResourceManager 协商一个容器的必要资源,启动一个 ApplicationMaster 来表示已提交的应用程序。通过使用一个资源请求协议,ApplicationMaster 协商每个节点上供应用程序使用的资源容器。执行应用程序时,ApplicationMaster 监视容器直到完成。当应用程序完成时,ApplicationMaster 从 ResourceManager 注销其容器,执行周期就完成了。
5.3 MapReduce架构概述
6. 大数据技术生态体系
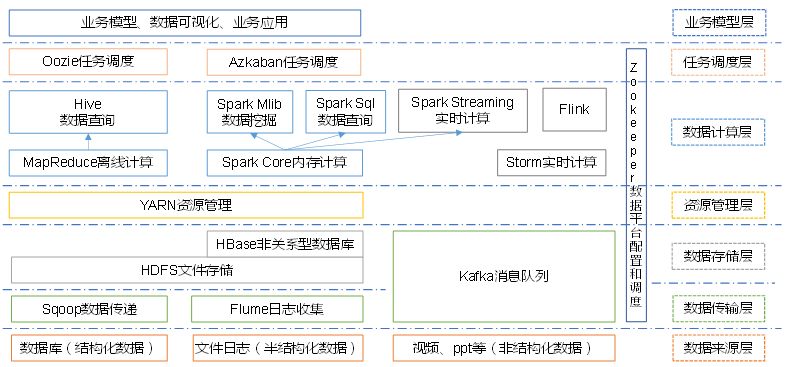
小结:大概描述就是 首先 大数据的根本就是分析计算数据,那一定要定位数据来源,数据来源大体包含三个方面,分别是 正规的数据库(结构化数据),其次还有文件日志(半结构化数据)以及通过一些爬虫手段获取的互联网数据(非结构化数据)这就组成了我们的**数据来源层**。
有了数据来源接下来就需要将这些数据传输到我们的分布式文件存储系统(HDFS)或者直接通过消息队列(kafka)将数据传输到数据计算层来做数据分析和运算,这里我们把专门做数据传输的技术层称之为*数据传输层***,同时保存到HDFS中后,我们成这块内容为 *数据存储层***。
有了具体的数据那后续就可以做数据分析运算了,这时候就要有 数据计算层 来完成,这部分大概根据数据结果的实效性可以分为两类数据分析运算的场景,一种是离线运算,一种实时运算,离线的话我们通常采用MapReduce和Hive来完成。实时的话就会用到Spark体系架构完成或者用Fink框架。
结合上面提到的概念,我们还要加入 资源管理层 主要有 YARN 来完成,它的主要工作就是来分配调度计算资源的,用来协作 MapReduce 作业。同时在实行数据运算的时候 我们考虑到服务器的资源分配以及人物先后执行的顺序,有加入了一个 任务调度层 专门来控制运算作业的执行时间和先后顺序
以上就是大数据架构体系的协作规则和架构说明,但是我们最后又考虑到 分布式集群的操作,各个版块和服务一定会交叉协同工作,所以最后利用Zookeeper来统一管理 分布式集群架构。OK,以上就是关于大数据技术生态体系的话术表现。
7. 推荐系统框架图

小结:以上的一个推荐系统的大概描述,首先一定从用户的行为开始入手,当用户购买一件商品加入购物车后,我们往往会给用户推荐相关的类似产品或者连带产品,这是目前电商系统很常见的一种营销手段。这个推荐的数据是如何产生的呢?
1.用户将商品加入购物车,这是会产生购物车数据,这就是我们的数据来源
2.利用数据传输层的相关技术将数据进行搜集处理然后通过Kafak消息队列直接将数据传输到 实时运算的框架中进行分析运算。
3.当 数据计算层 把数据分析运算后会得到最终的结果,根据结果为依据找到相关的类似商品的数据进行整合。
4.最后回到电商系统中 的推荐模块 通过调用接口的方式获取最终的分析处理后整合的商品数据的结果,将其展示到客户端页面中。
上面大概就是一个推荐的流程,你学到了吗!!!
三、Hadoop运行环境搭建(重点)
1. 虚拟机环境准备
1). 准备模板机(安装最小化的Linux系统)
yum安装必要的插件
sudo yum install -y epel-release sudo yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git修改 /etc/hosts 文件
192.168.2.100 hadoop100 192.168.2.101 hadoop101 192.168.2.102 hadoop102 192.168.2.103 hadoop103 192.168.2.104 hadoop104 192.168.2.105 hadoop105 192.168.2.106 hadoop106 192.168.2.107 hadoop107 192.168.2.108 hadoop108设置Linux的防火墙开机不自启
systemctl stop firewalld systemctl disable firewalld创建 atguigu 用户
useradd atguigu修改/etc/sudoers文件 配置atguigu用户具有root权限
在第92行的位置加上以下内容 atguigu ALL=(ALL) NOPASSWD:ALL :wq! 强制保存退出。在/opt目录下创建两个文件夹
mkdir /opt/software --放置需要安装的软件的安装包 madir /opt/module --软件的安装目录配置 两个文件夹 属于 atguigu 用户和 atguigu 组
chown atguigu:atguigu /opt/software chown atguigu:atguigu /opt/module
2). 准备开发用的虚拟机
根据模板机克隆一台机器
- 根据克隆的步骤进行克隆就可以(参考Linux阶段的克隆操作)
- 启动虚拟机
修改克隆机的主机名
1.编辑hostname文件 vim /etc/hostname 2.修改主机名称 hadoop101 3.重启机器 reboot修改克隆机的ip
1.编辑ifcfg-ens33文件 vim /etc/sysconfig/network-spcripts/ifcfg-ens33 2.重点修改的一下标注的地方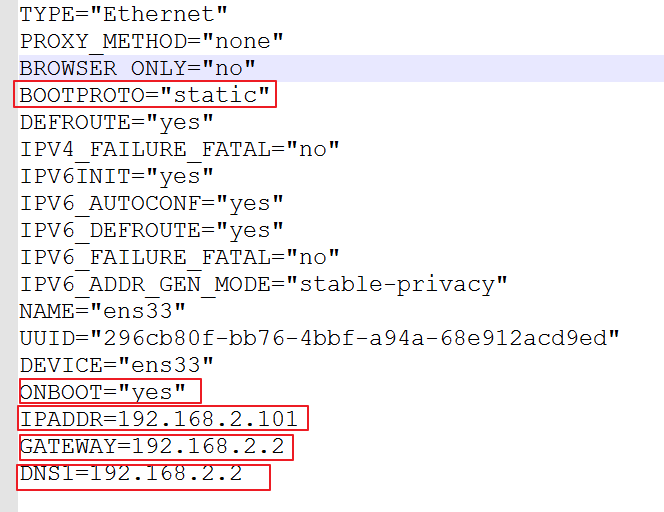
利用FinallShell工具连接Linux
2. 在准备好开发机hadoop101安装JDK
概述:本小节主要讲解在Linux中如何安装jdk,首先要明白Hadoop是用Java开发的,换言之Hadoop就是一款Java写的软件,那么想要运行Hadoop必然需要jdk环境。在Linux中安装Jdk和Windows中安装原理相同,只不过在Linux中Jdk的体现形式是一个 tar.gz的压缩包而Windows中是一个可视化安装程序。
1). 卸载现有JDK
注意:如果首次安装就没必要进行这一步,如果想更换jdk,非首次安装则需要先把已有的卸载掉
rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps2). 将jdk的tar包导入到Linux中opt目录下的software下
在我们的FinallShell工具中,直接找到opt目录下的software文件夹,将Windows目录下的jdk-8u212-linux-x64.tar.gz 包拖拽到software文件夹里即可3).解压jdk压缩包到opt目录下的module文件夹中
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/4). 配置jdk的环境变量
概述:接下来我们就要配置jdk的环境变量,思路和在windows系统下配置环境变量类似。这里注意一下,在Linux中 我们可以通过修改 Linux的核心profile文件来添加jdk的环境变量,但是我们通常不会这么做,原因就是不希望改动Linux原有的核心文件,以免引起不必要的麻烦,那我们怎么做呢?推荐方式就是自己在指定的目录下创建一个xxx.sh文件用来充当我们自己的配置文件。当Linux系统启动后会加载profile 文件,而profile文件中的脚本会循环遍历加载 /etc/profile.d/ 目录下所有以sh为后缀名的文件,所以我们自己创建xxx.sh文件也就被加载到了。固然环境变量也就生效了!
在/etc/profile.d/目录下新建文件 my_env.sh文件
sudo vim /etc/profile.d/my_env.sh在my_env.sh文件中添加一下内容
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin保存后退出
:wqsource 重新加载 /etc/profile文件,环境变量生效
source /etc/profile验证jdk是否安装以及配置成功
java -version如下图就成功了!
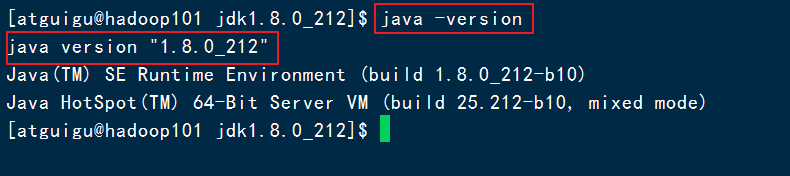
如果没成功就reboot重启Linux,如果没问题就不用了重启!
3. 在开发机hadoop101安装Hadoop
概述:终于要安装hadoop了,hadoop我们把它看做适合jdk是同一类型的软件,jdk怎么操作hadoop也怎么操作就可以!
1). 将hadoop的tar包拖拽到/opt/software目录下
2). 将hadoop解压缩到/opt/module目录下
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/3).配置hadoop的环境变量
注意:hadoop中有一个特别之处,就是在hadoop的目录下的bin目录和sbin目录都是hadoop的执行脚本,所以我们在配置hadoop的环境变量的时候要注意把这两个都配上才可以!剩下其他的操作都和jdk一样了!
打开/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh在my_env.sh文件末尾添加如下内容:(shift+g)
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin保存退出
:wqsource 重新加载 /etc/profile文件,环境变量生效
source /etc/profile验证hadoop是否安装以及配置成功
hadoop version
如图所示表示安装成功!
4. Hadoop目录结构
- bin: bin目录是Hadoop最基本的管理脚本和使用脚本所在的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop
- etc: Hadoop配置文件所在的目录,包括:core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml等配置文件。
- include:对外提供的编程库头文件(具体的动态库和静态库在lib目录中),这些文件都是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。
- lib:包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。
- libexec:各个服务对应的shell配置文件所在的目录,可用于配置日志输出目录、启动参数(比如JVM参数)等基本信息。
- sbin: Hadoop管理脚本所在目录,主要包含HDFS和YARN中各类服务启动/关闭的脚本。
- share: Hadoop各个模块编译后的Jar包所在目录,这个目录中也包含了Hadoop文档。
四、Hadoop运行模式
前言:本章节主要来学习Hadoop的运行模式,何谓运行模式呢?简单的讲就是Hadoop该如何运作起来,或者理解为玩Hadoop的游戏规则,是单台机器运行,还是多台协作运行,不同的运行模式有不一样的配置和处理。Hadoop中一共存在三种运行模式, 本地模式、伪分布式模式、完全分布式模式。
本地模式:在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统。
伪分布式:这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点: (NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode) ,同理 集群中的结点由一个JobTracker和若干个TaskTracker组成,JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。一个机器上,既当namenode,又当datanode,或者说 既 是jobtracker,又是tasktracker。没有所谓的在多台机器上进行真正的分布式计算,故称为”伪分布式”。
完全分布式:真正的分布式,由3个及以上的实体机或者虚拟机组件的机群。
注意:我们在课程中 用本地模式来入门开胃,然后集中火力做 完全分布式 伪分布式只做了解即可,没有太大意义!
1.本地运行模式
本小节主要就是感受一把Hadoop的运行过程,根据Hadoop官方提供的示例来操作几个Hadoop的基本功能点。更重要的是掌握基本操作Hadoop的步骤和思路。
案例1需求描述:利用hadoop的grep过滤功能,将一批文件中的一些内容过滤出来。
实现步骤:
1.1 在hadoop的解压目录创建一个文件夹input,作为需要过滤的文件的输入目录
mkdir input*1.2 将hadoop目录下的 etc/hadoop/.xml文件都复制到 input目录下,作为被过滤文件**
cp /etc/hadoop/*.xml input1.3 执行 bin/hadoop 命令,运行share/hadoop/mapreduce/目录下的hadoop-mapreduce-examples-3.1.3.jar包中的 grep 过滤功能,并限制一定的规则
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'1.4 最后在output目录下查看过滤的结果即可!
案例2需求描述:利用Hadoop完成经典wordcount(单词统计),就是针对一些文件计算统计里面相同单词的个数。
实现步骤:
1.1 创建在hadoop-3.1.3文件下面创建一个wcinput文件夹
mkdir wcinput1.2 在wcinput文件下创建一个word.txt文件
cd wcinput1.3 编辑word.txt文件
vim word.txt
在文件中输入如下内容(内容随意)
hadoop yarn
hadoop mapreduce
atguigu
atguigu1.4 回到Hadoop目录/opt/module/hadoop-3.1.3 执行程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput1.5 查看结果
cat wcoutput/part-r-00000
看到如下结果:
atguigu 2
hadoop 2
mapreduce 1
yarn 12.完全分布式运行模式(重点掌握)
本章节是重中之重,主要讲解完全分布式运行模式。
2.1 准备3台服务器
为了满足集群的环境,我们需要准备三台服务器,准备方式就是根据我们之前做好的模板机进行克隆即可,但是需要注意,三台服务器的的 静态ip地址和主机名都要修改一下,以便区分!
2.1.1 克隆第一台
修改主机名为hadoop102
修改ip地址为:192.168.2.102
2.1.2 克隆第二台
修改主机名为hadoop103
修改ip地址为:192.168.2.103
2.1.3 克隆第三台
修改主机名为hadoop104
修改ip地址为:192.168.2.104
2.2 集群分发脚本的应用场景
场景介绍:
上面我们已经准备好了三台服务器,并且都各自修改了主机名和ip地址。但是我们知道 需要额必备软件以及环境变量还没有配置,如果机械的一台一台配置也可以但是这样会引发大量的重复性工作,没有必要。如何能避免重复配置呢,最好是值在一台机器进行修改 然后将修改的配置信息同步到集群的所有机器那就完美了!这时候就要用到 分发脚本 的方案!
2.2.1 scp 安全拷贝
scp含义:
scp命令可以实现服务器与服务器之间的数据拷贝
基本语法:
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname 命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
案例实操:
前提:在 hadoop102 hadoop103 hadoop104 都已经创建好的 /opt/module
/opt/software 两个目录, 并且已经把这两个目录修改为atguigu:atguigu
sudo chown atguigu:atguigu -R /opt/module
1).在hadoop101上,将hadoop101中/opt/module/目录下所有内容拷贝到hadoop102上的/opt/module/目录下。
scp -r /opt/module/* atguigu@hadoop102:/opt/module/2).在hadoop103上,将hadoop101中/opt/module/目录下的所有内容拷贝到hadoop103的/opt/module/目录下。
scp -r atguigu@hadoop101:/opt/module/* /opt/module/3).在hadoop103上,将hadoop101中/opt/module/目录下的所有内容拷贝到hadoop104的/opt/module/目录下。
scp -r atguigu@hadoop101:/opt/module/* atguigu@hadoop104:/opt/module/4).在任意一台机器上,将hadoop101中的/etc/profile.d目录下的my_env.sh配置文件分别复制到hadoop102、hadoop103、hadoop104上
1. scp -r /etc/profile.d/my_env.sh root@hadoop102:/etc/profile.d/
2. scp -r /etc/profile.d/my_env.sh root@hadoop103:/etc/profile.d/
3. scp -r /etc/profile.d/my_env.sh root@hadoop104:/etc/profile.d/2.2.2 rsync远程同步工具
功能描述:
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:
用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
基本语法:
rsync -av $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
选项参数说明
| 选项 | 功能 |
|---|---|
| -a | 归档拷贝 |
| -v | 显示复制过程 |
案例实操:
把hadoop102机器上的/opt/software目录同步到hadoop103服务器的/opt/software目录下(没有实际意义的操作只是为了练手)
rsync -av /opt/software/* atguigu@hadoop103:/opt/software/2.2.3 分发脚本的应用
概述:前面其实我们已经是实现了服务器之间的文件目录拷贝传递了,但是每次都得执行命令来实现,还是比较麻烦的,干脆一步到位,通过编写一个脚本 通过执行脚本来实现信息拷贝。
前提: 在/home/atguigu/bin这个目录下存放的脚本,atguigu用户可以在系统任何地方直接执行。
脚本实现:
1). 在/home/atguigu/bin目录下创建xsync文件
[atguigu@hadoop102 opt]$ cd /home/atguigu
[atguigu@hadoop102 ~]$ mkdir bin
[atguigu@hadoop102 ~]$ cd bin
[atguigu@hadoop102 bin]$ vim xsync2). 在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
3). 修改文件的执行权限
chmod 777 xsync4). 将脚本复制到/bin中,以便全局调用
sudo cp xsync /bin/5). 测试脚本
xsync test.txt2.3 分布式集群规划
概述:接下来我们就要搭建Hadoop集群了,在操作之前一定要有具体的集群规划,集群规划其实就是把Hadoop中的核心组件如何安排到每台机器上。
分析: 通过前面的介绍我们知道 在Hadoop集群当中先要考虑数据的存储以及资源调度的安排。那就会涉及到NameNode 、ResourceManager 、SecondaryNameNode 、DataNode 、 NodeManager。如何把这些组件分布到每一台机器上,就得合理分析一下。
NameNode 、ResourceManager 、SecondaryNameNode 这三个组件相对来说比较耗费资源,我们通常把他们分布到不同的机器上。所以三台机器每一台分布一个。
DataNode是具体存储数据的,因为三台机器都具备存储空间,那每一台都分布一个DataNode
NodeManager是负责每一台机器的资源的管理,因此三台机器每一台也分布一个NodeManager
hadoop102 NameNode DataNode NodeManager
hadoop103 ResourceManager DataNode NodeManager
hadoop104 SecondaryNameNode DataNode NodeManager
2.4 搭建完全集群
1.先删除每个节点中hadoop安装目录下的 data 和 logs目录,如果是最新解压配置的hadoop集群,并没有这两个目录就不需要进行删除这步。
2.在hadoop-env.sh文件中,配置JAVA_HOME 的环境变量,这是因为Hadoop运行的时候需要java的环境变量。
3.配置Hadoop的4大核心配置文件
core-site.xml 这个是hadoop总的核心配置文件,集群加载启动的时候首先会加载解析此配置文件,具体配置内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!--cmeNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:9820</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.data.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 --> <property> <name>hadoop.proxyuser.atguigu.hosts</name> <value>*</value> </property> <!-- 配置该atguigu(superUser)允许通过代理用户所属组 --> <property> <name>hadoop.proxyuser.atguigu.groups</name> <value>*</value> </property> <!-- 配置该atguigu(superUser)允许通过代理的用户--> <property> <name>hadoop.proxyuser.atguigu.users</name> <value>*</value> </property> </configuration>hdfs-site.xml 这个是hdfs的核心配置文件,具体配置内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!--指定NameNode数据的存储目录--> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.data.dir}/name</value> </property> <!--指定DataNode数据的存储目录--> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.data.dir}/data</value> </property> <!--指定SecondaryNameNode数据的存储目录--> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file://${hadoop.data.dir}/namesecondary</value> </property> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> </configuration>yarn-site.xml 这个是Yarn的核心配置文件,具体内容如下:
<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties --> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- yarn容器允许分配的最大最小内存 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <!-- yarn容器允许管理的物理内存大小 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- 关闭yarn对物理内存和虚拟内存的限制检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>mapred-site.xml 这是MapReduce配置文件,配置内容如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>4. 启动HDFS,单独启动每一台机器上的组件(重点)
因为hdfs分布式文件系统本质是一个文件系统,固然在使用之前要进行格式化,那么在哪台机器格式化呢,就是hdfs的大哥NameNode所在的节点进行格式化,格式化命令如下:
[atguigu@hadoop102 hadoop]$ hdfs namenode -format
- 启动HDFS文件系统,注意:我们现在是每台机器逐个启动所以一定要清晰之前定的集群规划的方案,现在要启动HDFS文件系统,而HDFS系统又包含 NameNode、SecondaryNameNode、DataNode,这三大组件有分别被规划在 NameNode在hadoop102、SecondaryNameNode在hadoop104、以及每一台机器上都有DataNode,所以启动流程如下:
在hadoop102上 启动NameNode 命令如下:
[atguigu@hadoop102 hadoop]$ hdfs --daemon start namenode在hadoop104上 启动SecondaryNameNode 命令如下:
[atguigu@hadoop104 ~]$ hdfs --daemon start secondarynamenode在hadoop102 hadoop103 hadoop104 都启动DataNode 命令如下:
[atguigu@hadoop102 hadoop]$ hdfs --daemon start datanode [atguigu@hadoop103 hadoop]$ hdfs --daemon start namenode [atguigu@hadoop104 hadoop]$ hdfs --daemon start namenode
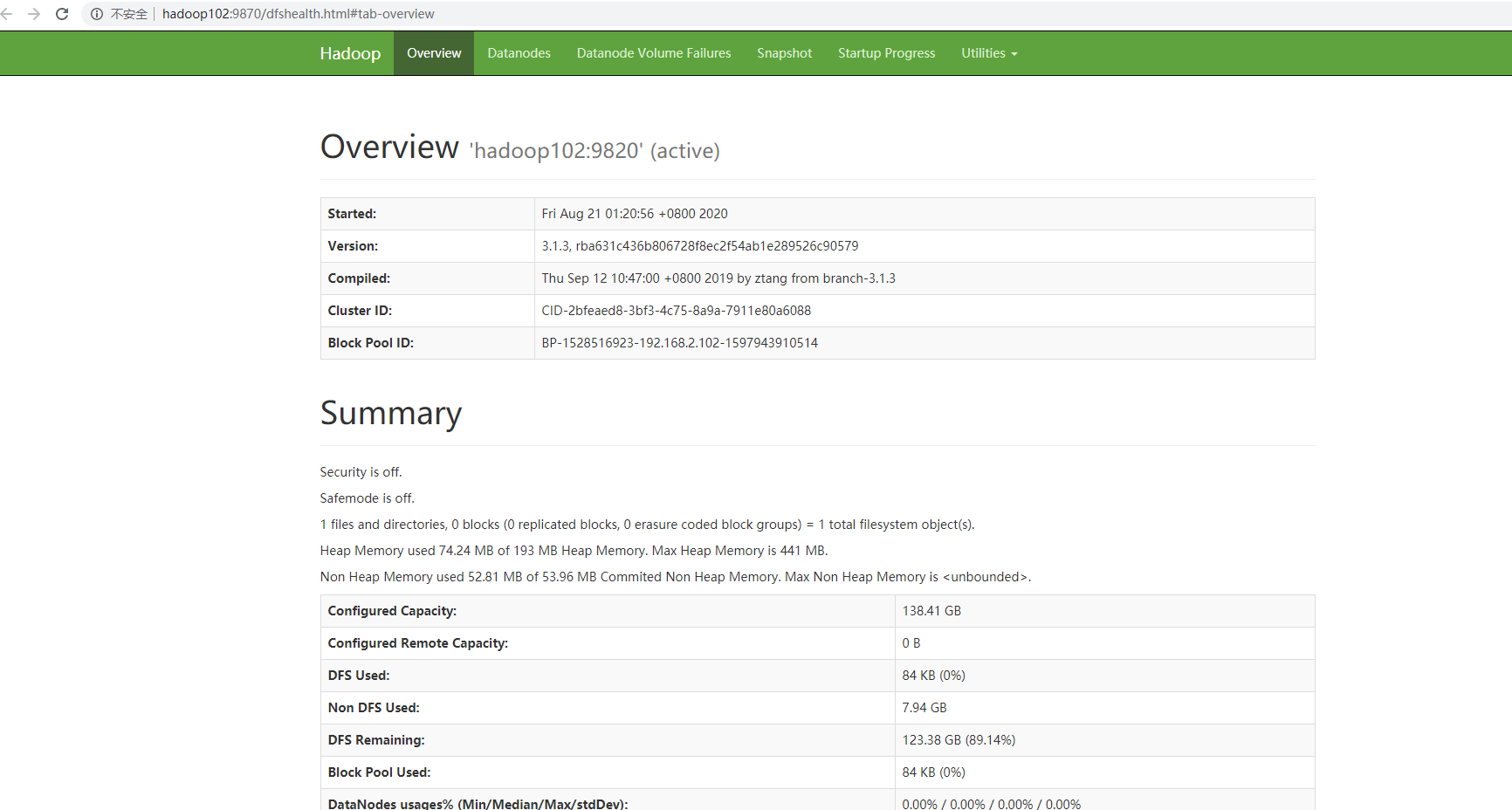
- 检测hdfs是否启动成功 Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息
5. 启动Yarn
根据集群规划,Yarn的ResourceManager我们分布在hadoop103上,NodeManager每一台机器上都存在所以启动流程如下:
1). 在hadoop103 启动resourcemanager 命令如下:
[atguigu@hadoop103 hadoop]$ yarn --daemon start resourcemanager2). 分别在hadoop102、hadoop103、hadoop104 启动nodemanager 命令如下:
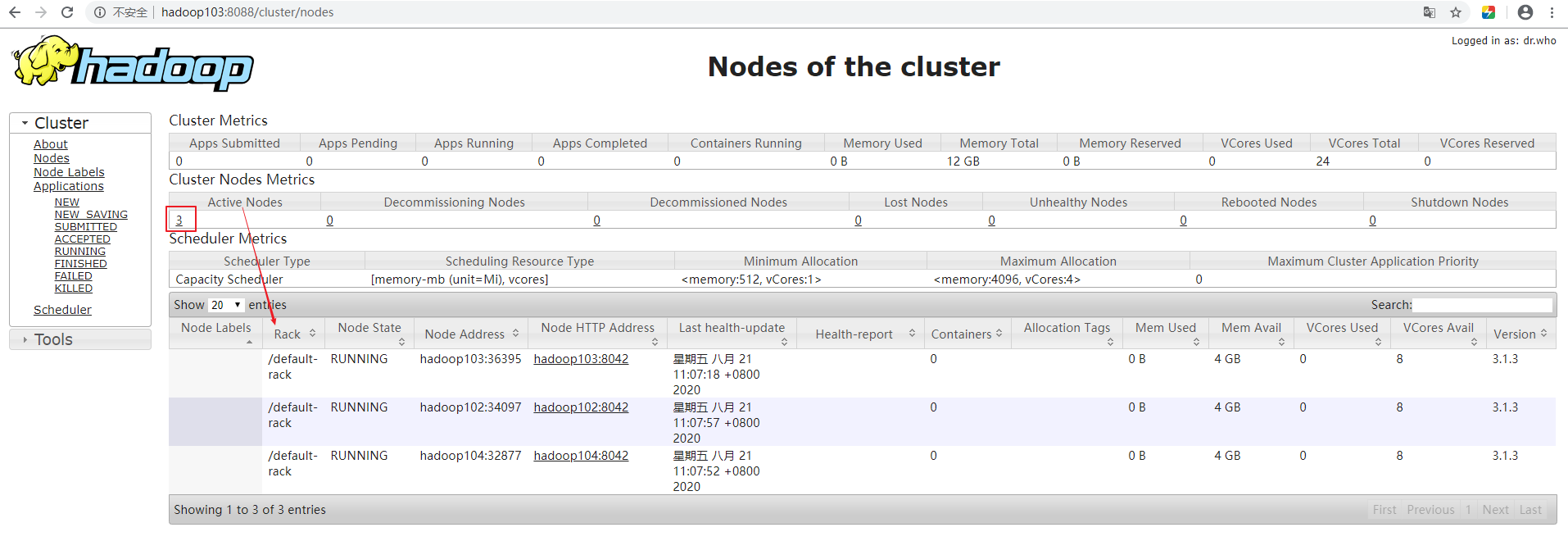
[atguigu@hadoop102 hadoop]$ hdfs --daemon start nodemanager [atguigu@hadoop103 hadoop]$ hdfs --daemon start nodemanager [atguigu@hadoop104 hadoop]$ hdfs --daemon start nodemanager3). 检测Yarn是否启动成功 Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息
6.简单测试使用集群
前言: 接下来简单测试试用一下我们搭建好的集群环境,操作的目标就是在HDFS 文件系统上上传文件以及运行一下简单的MapReduce程序即可!但是这里需要我们注意的一个 问题就是 HDFS系统所指向的物理路径究竟是哪 一会应该往哪个路径下上传文件!
问题一:HDFS文件系统怎么定位?
首先我们清楚,当前集群是运行在Linux上的,而Linux又是在Windows系统中的通过虚拟机的方式运行的,所以HDFS文件系统本质上也是占用了我们当前电脑硬盘的一部分,通过hadoop体系为HDFS分配出的一块存储空间。但是一定要注意它具有独立性,是由Hadoop独立来管理的。
问题二:在操作HDFS文件系统的时候如何理解它的输入路径和输出路径?
Hadoop如何识别是Linux路径还是HDFS路径呢?本质上还得看 Hadoop的核心配置文件的fs.defaultFS的配置信息。
当前我们搭建的集群配置如下:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9820</value>
</property>参考官网默认配置如下:
<property>
<name>fs.defaultFS</name>
<value>file:///</value>
</property>对比分析:
1). Hadoop的fs.defaultFS的默认配置是file:/// 如果解析的是这个配置,file:/// 本质上所表示的就是Linux本地路径,那么在操作中写输入输出就按照Linux的规则正常写就行,例如编写执行wordcount程序的命令如下:
[atguigu@hadoop102 hadoop]$ hadoop jar share/hadoop/mapredece/hadoop-mapreduce-ecanples.jar wordcount wcinput/wc.input wcoutput2). 如果我们自己修改了core-site.xml 核心配置文件配置 fs.defaultFS 的值为hdfs://hadoop102:9820 那么意味着在解析输入输出路径的时候指向的是HDFS系统维护的目录结构 在HDFS系统底层维护的路径是 /user/atguigu/wcinput 所以如果是在这个情况下我们要操作wordcount程序就应该这么写了 命令如下:
[atguigu@hadoop102 hadoop]$ hadoop jar share/hadoop/mapredece/hadoop-mapreduce-ecanples.jar wordcount /user/atguigu/wcinput/wc.input /user/atguigu/wcoutputOK! 有了上面的内容作为支撑,下面我们就正式对Hadoop集群进行简单测试操作!!!
6.1 在HDFS中创建一个目录 /user/atguigu/input 目录
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfs -rm -R /user/atguigu/input6.2 将hadoop安装目下的wcinput/wc.input 文件上传到HDFS文件系统上的 /user/atguigu/input 目录下
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfs -put wciput/wc.input /user/atguigu/input6.3 如何在HDFS上查看具体存储的文件
DataNode的存储目录:
[atguigu@hadoop103 hadoop-3.1.3]$ cd data/data/current/BP-1528516923-192.168.2.102-1597943910514/current/finalized/subdir0/subdir0/6.4 测试Yarn是否能正常使用 还是以Mapreduce的wordcount程序为例
[atguigu@hadoop104 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /user/atguigu/input /user/atguigu/output6.5 在hdfs上面查看执行后的结果
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfs -cat /user/atguigu/output/part-r-000007. SSH免密登录
存在的问题: 集群启动和关闭,目前我们都是通过单点操作完成的,这样很不方便,于是就考虑能不能在一台机器上就能搞定集群的启动和关闭?
分析:
参照之前的脚本分发的思路,我们可以编写一个集群启动和关闭的脚本,就是把哪些在每一台机器上输入的命令封装到一个脚本中,然后通过执行脚本来实现集群启动关闭的目的。
脚本的大概思路:
登录到hadoop102 启动/关闭 namenode
登录到hadoop104 启动/关闭 secondarynamenode
登录到hadoop102 hadoop103 hadoop104 启动/关闭 datanode
登录到hadoop103 启动/关闭 resourcemanager
登录到hadoop102 hadoop103 hadoop104 启动/关闭 nodemanager
如何登录远程的机器:
语法:ssh ip/主机名
无密钥配置: 单纯的 ssh 命令操作,虽然可以只在一台机器操作了但是操作步骤较多,而且登录的时候每次都需要输入密码,我们接下来要做到免密登录+脚本控制
免密登录的原理:
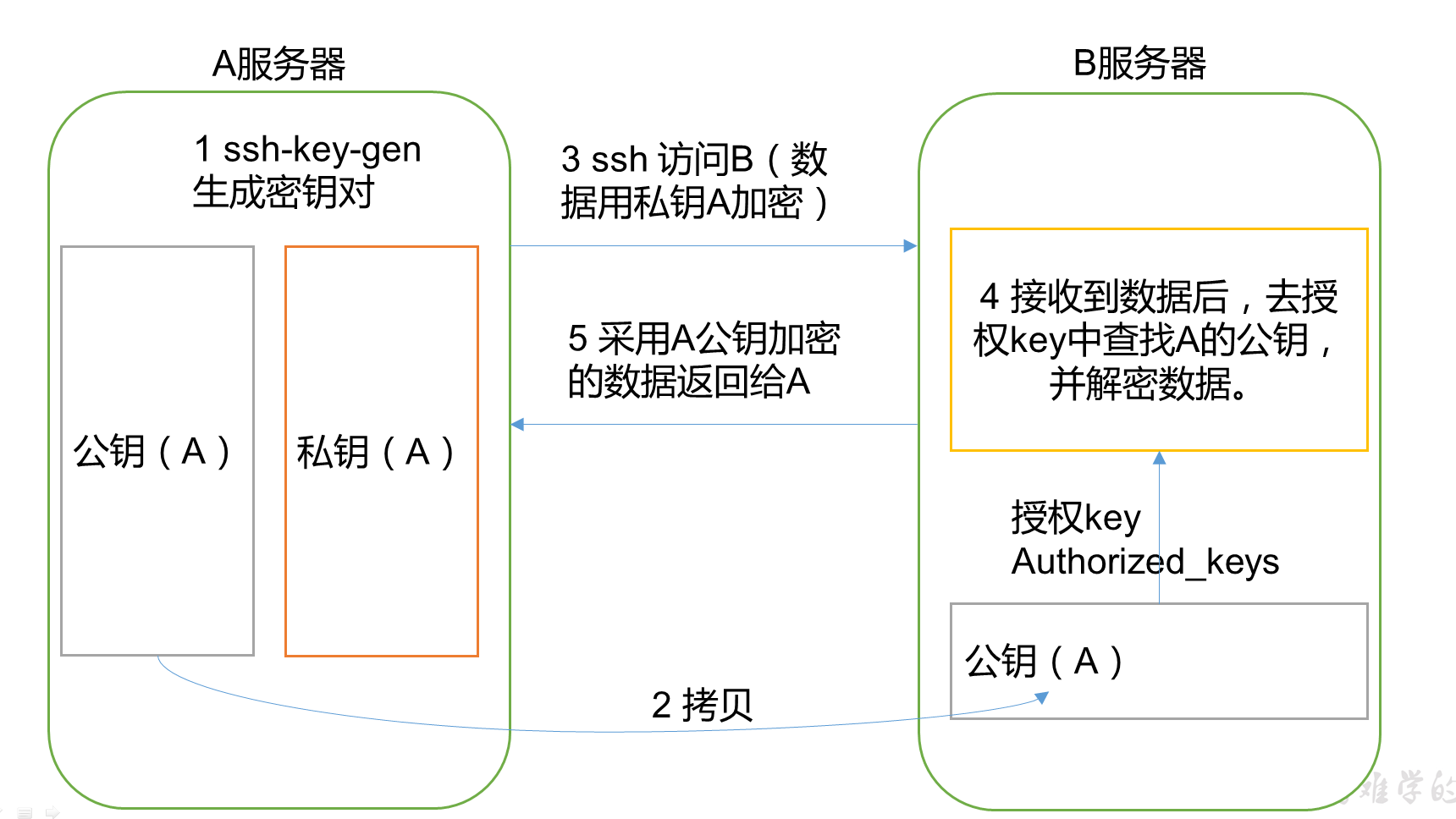
实现步骤:
1). 生成公钥和私钥:
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa然后敲(四次回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
2). 将公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop1043). 注意,集群机器的配置
还需要在hadoop103上采用atguigu账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop104上采用atguigu账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop102上采用atguigu账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;
4). .ssh文件夹下(~/.ssh)的文件功能解释
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
8.集群的群起操作
当配置过了ssh免密登录,就可以对hadoop进行群起了(多台机器通过脚本一起启动),群起的脚本hadoop已经帮我们内置好了直接使用即可!但是要最终完成群起操作我们必须让启动/关闭脚本知道 NameNode SecondaryNameNode DataNode ResourceManager NodeManager都在哪一台机器上分配,这个怎么做到呢?这个是由 hadoop安装目录下的 etc/hadoop/workers 配置文件来控制。
- 配置 workers 文件,内容如下:
hadoop102
hadoop103
hadoop104注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
启动集群
1). 如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
[atguigu@hadoop102 ~]$ hdfs namenode -format2). 启动HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh3). 在配置了ResourceManager的节点(hadoop103)启动YARN
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh9.群起群停脚本的编写
上面我们已经完成对集群的群起,但是还不够完美,我们操作执行了两个脚本才启动了hdfs和yarn,虽然hadoop也给我们提供了start-all.sh 脚本,但是通常开发中不建议使用,因为start-all.sh脚本启动的话会默认启动一些不必要的组件。我们想更加完美的群起 只执行一个脚本就能把hdfs和yarn都启动或者停止。接下来我们自己封装一个脚本来实现,步骤如下:
1). 进入到/home/atguigu/bin目录下创建一个群起/群停脚本,这样操作为了在任何位置都能执行脚本
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 ~]$ vim mycluster.sh2). 编写脚本内容:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit
fi
case $1 in
"start")
echo "==================START HDFS==================="
ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/start-dfs.sh
echo "==================START YARN==================="
ssh hadoop103 /opt/module/hadoop-3.1.3/sbin/start-yarn.sh
;;
"stop")
echo "==================STOP YARN==================="
ssh hadoop103 /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh
echo "==================STOP HDFS==================="
ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
;;
*)
echo "Input Args Error!!!!"
;;
esac
3). 保存后退出,然后赋予脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 myhadoop.sh4). 分发/home/atguigu/bin目录,保证自定义脚本在三台机器上都可以使用
[atguigu@hadoop102 ~]$ xsync /home/atguigu/bin/10.编写统一查看jps的脚本
上面我们做了一个频繁的操作,就是总是在每一机器上输入 jps 命令,来查看当前机器的java进程,而且每次输入都是切换到服务器上输入,很麻烦,接下来我们要实现在一台机器就能查看整个集群的java进程。
1). 进入到/home/atguigu/bin目录下创建一个查看jps的脚本
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 ~]$ vim jpsall.sh2). 编辑脚本内容如下:
#!/bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo "***************$i JPS****************"
ssh $i /opt/module/jkd1.8.0_212/bin/jps
done3). 保存后退出,然后赋予脚本执行权限
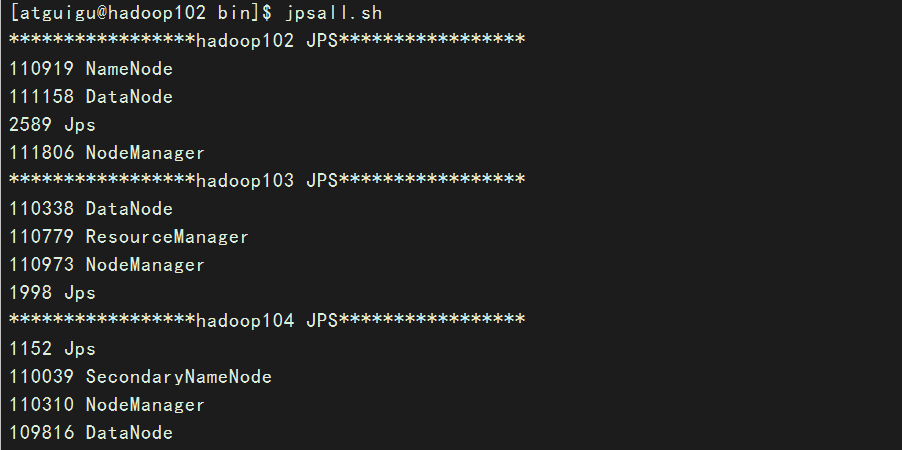
[atguigu@hadoop102 bin]$ chmod 777 jpsall.sh4). 测试
[atguigu@hadoop102 bin]$ jpsall.sh 结果如下:
11.历史服务器的使用
这一小节主要介绍hadoop的历史服务器的使用!什么是历史服务器呢?举个例子就是我们在YARN上跑的一些job的历史记录,当重启YARN后之前执行过的job任务记录就会消失,hadoop为了更好的追溯和记录这些job执行记录专门提供了一个历史服务器,只要我们在Hadoop中配置了历史服务器那么以后就可以很方便查看执行过的所有job。
1).配置mapred-site.xml
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml在该文件里面增加如下配置:
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>2). 分发配置
[atguigu@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml3). 在hadoop102启动历史服务器
[atguigu@hadoop102 hadoop]$ mapred --daemon start historyserver4). 查看历史服务器是否启动
[atguigu@hadoop102 hadoop]$ jps- web端查看历史服务器的图形化界面
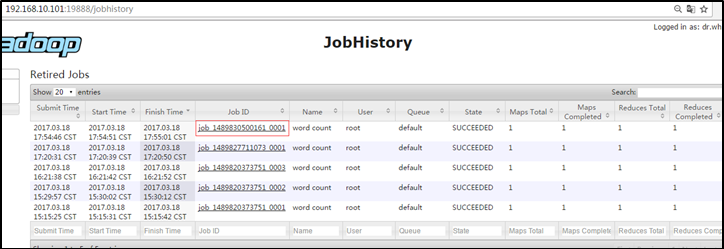
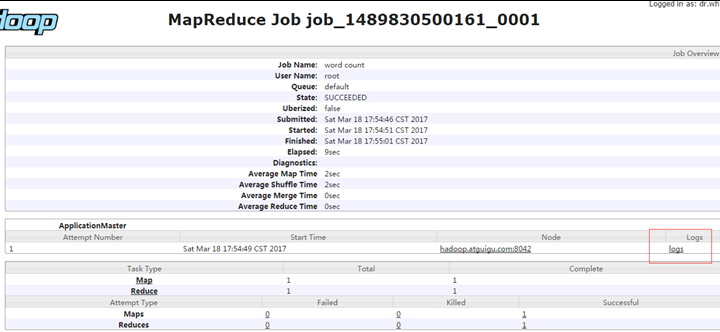
http://hadoop102:19888/jobhistory
12.配置日志的聚集
本小节主要对hadoop中的日志进行合理性的管理,方便我们更好的查阅。默认情况下 Hadoop作业执行的日志保存在hadoop的安装目录下logs下面。我们可以在linux上直接查看,但是这样操作不够人性化,查阅起来也比较麻烦。所以我们可以在执行job任务的时候产生日志后,让它自动的保存到hdfs系统中,这样就可以在网页中通过访问HDFS系统的web端地址来查看日志了!如果想完成上述操作需要我们进行以下几步配置和操作。
1)配置yarn-site.xml
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml内容如下:
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>2)分发配置
[atguigu@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml3)关闭NodeManager、ResourceManager和HistoryServer
[atguigu@hadoop103 ~]$ stop-yarn.sh
[atguigu@hadoop102 ~]$ mapred --daemon stop historyserver4)启动NodeManager 、ResourceManage和HistoryServer
[atguigu@hadoop103 ~]$ start-yarn.sh
[atguigu@hadoop102 ~]$ mapred --daemon start historyserver5)执行wordcount程序
[atguigu@hadoop102 ~]$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output6)Web端查看日志
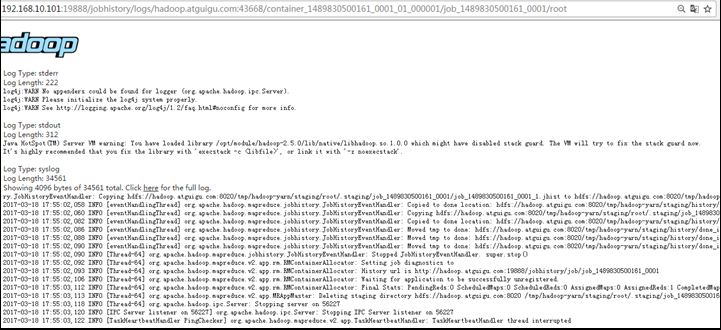
http://hadoop102:19888/jobhistory
13. 集群时间同步
本小节主要操作在集群环境下,每一台服务器之间的时间同步。时间同步是很有必要的,因为在多台机器协同工作的时候,必然要求时间统一 要不然就会出问题。以下内容只要求大致了解 这项工作一般在运维的范畴。
1)时间服务器配置(必须root用户)
(0)查看所有节点ntpd服务状态和开机自启动状态
[atguigu@hadoop102 ~]$ sudo systemctl status ntpd
[atguigu@hadoop102 ~]$ sudo systemctl is-enabled ntpd(1)在所有节点关闭ntpd服务和自启动
[atguigu@hadoop102 ~]$ sudo systemctl stop ntpd
[atguigu@hadoop102 ~]$ sudo systemctl disable ntpd(2)修改hadoop102的ntp.conf配置文件
[atguigu@hadoop102 ~]$ sudo vim /etc/ntp.conf修改内容如下:
a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
改为(就是把注释去掉):
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
改为(都加上注释):
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10(3)修改hadoop102的/etc/sysconfig/ntpd 文件
[atguigu@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpd增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes(4)重新启动ntpd服务
[atguigu@hadoop102 ~]$ sudo systemctl start ntpd(5)设置ntpd服务开机启动
[atguigu@hadoop102 ~]$ sudo systemctl enable ntpd2)在其他机器进行时间同步操作(必须root用户)
(1)在其他机器配置1分钟与时间服务器同步一次
[atguigu@hadoop103 ~]$ sudo crontab -e编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop102(2)修改任意机器时间
[atguigu@hadoop103 ~]$ sudo date -s "2018-8-08 08:08:08"(3)一分钟后查看机器是否与时间服务器同步
[atguigu@hadoop103 ~]$ sudo date


